Accueil > Pour en savoir plus > Sciences formelles > Intelligence artificielle > "Etat de l’art et prospective concernant l’intelligence artificielle (IA) (…)
"Etat de l’art et prospective concernant l’intelligence artificielle (IA) dans les domaines artistiques (arts numériques) en France, au Québec Canada et en Californie" par Jacques Hallard avec Bastien Maleplate
mardi 3 septembre 2019, par ,
Etat de l’art et prospective concernant l’intelligence artificielle (IA) dans les domaines artistiques (arts numériques) en France, au Québec Canada et en Californie
Jacques Hallard , Ingénieur CNAM, site ISIAS, avec la collaboration scientifique et technique de Bastien Maleplate 03/08/2019
Série : L’ère des technologies numériques (ou digitales) et de l’intelligence artificielle (IA)

C :\Users\Jacques\Documents\Artificial Intelligence & AI & Machine Learning PLEASE CRE… Flickr_fichiers\30212411048_2a1d7200e2_n.jpg
Image 1 - Artificial Intelligence & AI & Machine Learning Mike MacKenzie Note

Résultat de recherche d’images pour ’ia arts’
Image 2 - Existe-t-il des IA créatives ? IA Lab 16 mars 2018 -Source
Plan : Introduction Sommaire Publications antérieures {{}}Auteurs
Le présent dossier s’inscrit dans une série intitulée « L’ère des technologies numériques (ou digitales) et de l’intelligence artificielle (IA) » dont les divers documents qui ont été postées sur le site ISIAS, sont à découvrir ici : Publications antérieuressur l’Intelligence Artificielle (IA).
Il s’agit ici à la fois d’un état de l’art [voir aussi Comment construire un état de l’art ?19 avril 2018] et d’une invitation à jeter un regard prospectif à partir de l’émergence des applications du numérique dans les domaines artistiques, avec les arts numériques. Lectures préalables suggérées : Qu’est ce que l’art numérique ? - Les arts numériqueshttps://www.cairn.info › revue-dossiers-du-crisp-2013-1-page-9de L .Diouf - 2013.
Selon les auteurs qui se sont exprimés et les secteurs concernés, l’Intelligence Artificielle est considérée tour à tour comme une invention humaine merveilleuse qui va solutionner des tas de problèmes, en faisant progresser les connaissances et générer des applications très utiles dans de nombreux domaines (santé, mobilité, éducation, militaire, etc…), ou bien, à l’inverse, l’IA est stigmatisée comme un ensemble de technologies lourdes d’incertitudes techniques (comme les dangers du cyberterrorisme), incertaines quant à leur utilité finale pour satisfaire nos besoins essentiels, leurs risques et menaces sur le plan sociétal, ou encore comme un engouement qui tient insuffisamment compte des ressources limitées de la planète Terre : certains, comme Jean-Marc Jancovici [voir aussi Qui suis-je ?] vont même – à l’instar de la nécessaire sobriété énergétique [voir également « Pour une société plus juste et plus durable »], jusqu’à recommander dès maintenant une indispensable sobriété numérique….
Ainsi, l’Intelligence Artificielle (IA) ne va-t-elle pas jusqu’à induire chez certains de nos contemporains une représentation anxiogène et une évocation effrayante ? Voir par exemple les réflexions d’Éric Roubert,(photo), rédacteur en chef de la publication Arts & Métiers Mag - Le magazine de la culture et de l’innovation sous le titrehttps://www.google.fr/url?sa=t&...« Les spectres derrière l’IA » par Eric 12 avril 2018 : « Il fallait un lieu comme le Collège de France, à Paris 5e, pour qu’Emmanuel Macron présente, fin mars 2018, les détails de la stratégie du gouvernement français en matière d’intelligence artificielle (IA). Le président de la République a sanctuarisé les éléments de cette stratégie que sont la recherche, l’ouverture des données et les enjeux sociaux ou éthiques. Mais, aujourd’hui, tout le monde s’interroge sur l’IA et sur la confiance qu’elle est censée inspirer. Les gros titres des journaux rappellent régulièrement les problèmes rencontrés : première collision mortelle d’un piéton par une voiture autonome ou 50 millions de données d’utilisateurs de Facebook utilisées à leur insu par, entre autres, une entreprise de marketing politique. Le scepticisme est grand chez les salariés vis-à-vis de l’intelligence artificielle. C’est du moins ce qui ressort d’une étude du Boston Consulting Group et de l’assureur Malakoff-Médéric intitulée « Intelligence artificielle et capital humain ». Salariés et dirigeants sont conscients des risques humains dont l’IA pourrait être porteuse. Ainsi, 56 % des répondants salariés craignent une déshumanisation du travail et une perte du lien social et 50 % redoutent une baisse des volumes de travail et d’emploi. Les dirigeants, eux, appréhendent surtout la multiplication des rapports et des contrôles (70 %), devant la déshumanisation et le volume du travail (57 %). Les manageurs partagent l’inquiétude sur le « reporting » et la déshumanisation du travail, en y ajoutant les questions d’éthique (64 % pour les trois items). L’intelligence artificielle a la capacité de changer le monde, mais à condition qu’elle soit largement acceptée par tous. Pour l’heure, ce n’est pas gagné…. » - Source : https://mag.arts-et-metiers.fr/les-spectres-derriere-intelligence-artificielle/ - Voir aussi du même auteur : Enquêtes , dont L’intelligence artificielle débarque à l’usine ; et des Interviews , dont L’Usine agile de Lille fait face à trois défis et L’intelligence artificielle rebat les cartes des emplois humains…
Ce dossier sur l’IA, à usage didactique, propose de répertorier un certain nombre de documents qui se rapportent tout spécialement aux Arts, un ensemble de domaines qui, selon Wikipédia, « représentent une forme de l’expression du vivant, généralement influencée par la culture et entraînée par une impulsion créatrice. Les arts font partie du ressenti et de la subjectivité, c’est pourquoi une définition finie n’est pas possible. Les éléments majeurs des arts sont la littérature, le spectacle vivant, dont la musique, la danse et le théâtre, les arts culinaires telles que, par exemple, la cuisine, la chocolaterie et la vinification, les arts médiatiques comme la photographie et le cinéma ainsi que les arts visuels qui comprennent le dessin, la peinture et la sculpture. Certaines formes d’art combinent un élément visuel au spectacle (par exemple un film) et l’écrit (par exemple, la bande dessinée). Des peintures rupestres préhistoriques, jusqu’à nos films modernes, l’art permet de raconter des histoires mais aussi de transmettre la relation de l’humanité avec son environnement… » - A lire en totalité sur ce site : https://fr.wikipedia.org/wiki/Arts
Il s’agit là de considérer plus particulièrement ce que Wikipédia introduit sous sa rubrique L’art numérique « qui désigne un ensemble varié de catégories de création utilisant les spécificités du langage et de dispositifs numériques : ordinateur, interface ou réseau. Il s’est développé comme genre artistique depuis la fin des années 19501. Portée par la puissance de calcul de l’ordinateur et le développement d’interfaces électroniques autorisant une interaction entre le sujet humain, le programme et le résultat de cette rencontre, la création numérique s’est considérablement développée en déclinant des catégories artistiques déjà bien identifiées. En effet, des sous-catégories spécifiques telles que la « réalité virtuelle », la « réalité augmentée », « l’art audiovisuel », « l’art génératif », ou encore « l’art interactif », viennent compléter les désignations techniques du Net-art, de la photographie numérique ou de l’art robotique. Soulignant la nécessité de construire un dialogue entre les médias traditionnels (peinture, sculpture, dessin) et les nouveaux médias, qui se sont tournés le dos abusivement, Hervé Fischer a proposé d’explorer ce que pourraient être les « beaux-arts numériques »… - Article complet sur ce site : https://fr.wikipedia.org/wiki/Art_num%C3%A9rique
Le sommaire ci-après comprend une vingtaine de documents qui ont été sélectionnés. Sont présentées au début deux contributions qui visent à décrire l’Intelligence Artificielle (IA) rédigée pour les débutants, d’une part, et à l’intention des êtres humains en général, d’autre part ; l’un des vocables utilisé : « Au commencement », fait un clin d’œil à Bereshit, le premier mot de la Bible. Selon Wikipédia, « Bereshit (en hébreu : בראשית « au commencement de ») « est la première section hebdomadaire du cycle annuel de lecture de la Torah. Elle est lue lors du premier et expliquée aux êtres humains, d’chabbat qui suit la fête de Sim’hat Torah (généralement en octobre) et correspond à Genèse 1:1-6:8. La parasha s’ouvre sur les récits de la création (מעשה בראשית Ma’asse Bereshit), clés de voûte de la philosophie, de l’éthique et de la tradition ésotérique juives, ainsi que pierre d’achoppement avec le polythéisme et la philosophie grecque. Elle se poursuit avec le récit des origines de l’humanité, s’achevant avec l’introduction de Noé… » - A lire en totalité ici : https://fr.wikipedia.org/wiki/Bereshit_(parasha)
D’autres documents sont exprimés sous forme de questions relatives simultanément à l’IA et aux œuvres d’art, et ouvrent un débat sur l’ouverture d’un tout nouveau marché de l’art et sur le devenir des œuvres artistiques réalisées par l’IA en concurrence avec les artistes, tels qu’on les considérait jusqu’à maintenant…
Puis quelques articles font référence aux nouveaux outils technologiques de la création artistique que sont les réseaux antagonistes génératifs, plus connus sous leur vocable anglo-saxon de GAN (pour ‘Generative Adversarial Networks’) : ce sont des modèles numériques génératifs qui sont eux-mêmes capables de produire des données.
Cette technologie fait appel à des algorithmes. D’après une introduction de Wikipédia, « Un algorithme est une suite finie et non ambiguë d’opérations ou d’instructions permettant de résoudre une classe de problèmes1. Le mot algorithme vient du nom d’un mathématicien perse du IXe siècle, Al-Khwârizmî (en arabe : الخوارزمي)2. Le domaine qui étudie les algorithmes est appelé l’algorithmique. On retrouve aujourd’hui des algorithmes dans de nombreuses applications telles que le fonctionnement des ordinateurs3, la cryptographie, le routage d’informations, la planification et l’utilisation optimale des ressources, le traitement d’images, le traitement de texte, la bio-informatique, etc… »
Voir un exemple d’algorithme de découpe un polygone quelconque en triangles (triangulation).- Voir l’article complet sur ce site : https://fr.wikipedia.org/wiki/Algorithme
Dans la technologie des réseaux antagonistes génératifs ou ‘GAN’, deux algorithmes interagissent, entretenant une relation gagnant-gagnant d’amélioration continue, dans le cadre d’une relation contradictoire. Ainsi, deux boucles de feedbacks transmettent, aux deux réseaux de neurones, l’identité des designs sur lesquels ils doivent s’améliorer : l’un est nommé le ‘Générateur (il reçoit l’identité des designs sur lesquels il a été démasqué par son ‘partenaire’, le ‘Discriminateur’ qui, lui, reçoit l’identité des designs sur lesquels il a été trompé par le ‘Générateur’…
Pour une découverte dynamique de cette technologique des GAN (2008), on peut passer un moment avec cette vidéo 5:31 ajoutée le 11 septembre 2018 : Pierre FAUTREL - À la découverte d’une IA artiste - Boma en Français - Pierre Fautrel - Co-fondateur du collectif ‘Obvious’ … qu’il a créé en 2017 avec ses deux amis d’enfance Hugo Caselles-Dupré et Gauthier Vernier. ‘Obvious’ est un collectif d’artistes, de chercheurs et d’amis qui travaille à la réalisation d’œuvres d’art à l’aide d’intelligence artificielle. Ils sont parvenus à mettre en valeur la notion de créativité chez une machine, au travers d’une série d’œuvres d’art générées sans aucune intervention humaine. En savoir plus sur https://fr.boma.global 👌 #ArtificialIntelligence #GenerativeArt #Ganisme - Catégorie : Science et technologie – Source : https://www.youtube.com/watch?v=xWS__kIJ7ws
Le document numéroté 13 dans le sommaire de ce dossier (« Image-to-Image Translation with Conditional Adversarial Netsdans ») introduit et expose de façon très pédagogique (en anglais, notamment à l’aide d’une vidéo), le mode de traitement des images et les applications concrètes qui se rapportent à différents usages de nature artistique.
Ensuite, quelques documents relatent des initiatives concrète qui ont été prises en France et au Québec Canada, pour l’enseignement de la création artistique à partir de la mise en œuvre de l’Intelligence Artificielle (IA).
Finalement, les trois derniers articles de ce dossier proposent des réflexions sur la réelle créativité artistique et en design de l’IA, sur l’affolement d’un nouveau marché de l’art pour ces nouvelles réalisations à partir du numérique, et sur une interrogation prospective : l’Intelligence Artificielle (IA) aidera-t-elle l’Homme à devenir plus humain ?
Pour parachever ce dossier, encore une définition de Wikipédia, utile à cet endroit : « La prospective, considérée comme une science de « l’homme à venir » par son créateur Gaston Berger1, vise, par une approche rationnelle et holistique, à préparer le futur de l’être humain. Elle ne consiste pas à prévoir l’avenir (ce qui relevait de la divination et relève aujourd’hui de la futurologie2) mais à élaborer des scénarios possibles et impossibles dans leurs perceptions du moment sur la base de l’analyse des données disponibles (états des lieux[[C’est-à-dire ?]->https://fr.wikipedia.org/wiki/Aide:Pr%C3%A9ciser_un_fait], tendances lourdes, phénomènes d’émergences) et de la compréhension et prise en compte des processus sociopsychologiques. Car comme le rappelle Michel Godet : « si l’histoire ne se répète pas, les comportements humains se reproduisent », la prospective doit donc aussi s’appuyer sur des intuitions liées aux signaux faibles, des analyses rétrospectives et la mémoire du passé humain et écologique (y compris et par exemple concernant les impacts environnementaux et humains des modifications géo-climatiques passées)2. Le prospectiviste se distingue ainsi du prolongateur de tendances comme du visionnaire qui élabore des scénarios à partir de révélations. La fonction première de la prospective est de synthétiser les risques et d’offrir des visions temporelles (scénarios) en tant qu’aide à la décision stratégique, qui engage un individu ou un groupe et affecte des ressources (naturelles ou non) plus ou moins renouvelables ou coûteuses sur une longue durée. Elle acquiert ainsi après avoir pris les risques nécessaires à une double fonction de réduction des incertitudes (et donc éventuellement de certaines angoisses) face à l’avenir, et de priorisation ou légitimation des actions ».
« La prospective est une démarche continue, car pour être efficace, elle doit être itérative et se fonder sur des successions d’ajustements et de corrections (boucles de rétroaction) dans le temps, notamment parce que la prise en compte de la prospective par les décideurs et différents acteurs de la société modifie elle-même sans cesse le futur (la prospective ne modifie pas le futur, elle se base sur le passé et le présent pour entrevoir le futur ; la prospective se nourrit d’elle-même et n’a aucune accroche de coïncidence avec des scénarios préétablis des acteurs politiques, elle n’est la propriété de personne, par contre la collecte, l’analyse et l’interprétation des données la font naître) qui est tout sauf prévisible. Elle s’appuie sur des horizons ou dates-butoir (ex : 2030, 20403, 2050, 2100) qui sont aussi parfois des échéances légales, et qui permettent à différents acteurs de faire coïncider leurs scénarios ou calculs de tendance… » - L’article complet est à lire sur ce site : https://fr.wikipedia.org/wiki/Prospective. Bonnes lectures !
Retour au début de l’introduction
3. Comment l’IA devient-elle un artiste ? - 2018 - Document ‘inprincipio.xyz/artiste/’
4. Google Deep Dream – Une IA capable de créer des œuvres d’art Par Bastien Lavril 3, 2017 Intelligence Artificielle
5. Création artistique et intelligence artificielle : de l’art ou du cochon ? Par Alexandre Lourié - Directeur général Groupe SOS Culture, directeur général Scintillo – 19/11/2017
6. Un tableau réalisé par une intelligence artificielle aux enchères, chez Christie’s
7. L’intelligence artificielle fait son trou dans le marché de l’art ParFrançois Manens - 06/03/2019 – Document ‘latribune.fr’
9. L’intelligence artificielle est-elle en train de devenir l’artiste de demain ? Article de Valentin Ginard – 3ème année – Cycle Mastère en 3 ans. Document ‘ecvdigital.fr/ecole-digitale’
11. Les réseaux antagonistes génératifs présentés par Wikipédia
13. Image-to-Image Translation with Conditional Adversarial Nets - University of California, Berkeley In CVPR 2017 - Jun-Yan Zhu etal
16. Intelligence artificielle au Québec Canada : les artistes sont-ils prêts ?Publié le mardi 22 janvier 2019
19. Existe-t-il des IA créatives ? IA Lab - P. Lemberger -16 mars 2018 – Document ‘weave.eu’
20. Quand l’intelligence artificielle affole le marché de l’art - Par Jean-Max Koskievic– Document ‘contrepoints.org’
21. L’Intelligence Artificielle aidera-t-elle l’homme à devenir plus humain ? par Alexandre | Déc 8, 2018 | Prospective | Document ‘inprincipio.xyz’
Retour au début de l’introduction
1.
L’Intelligence Artificielle (IA) pour les débutants avec ‘inprincipio.xyz’ – Document ‘InPrincipio.xyz’
Au commencement Illustration -
Il y eut la machine à vapeur, puis l’électricité et plus récemment Internet. Ces révolutions, dites industrielles, ont fait basculer nos sociétés et ses modes de vie.
Mais utiliser le terme de révolution pour désigner l’ère de l’Intelligence Artificielle est un euphémisme tant elle tend à réunir à elle-seule l’ensemble des plus grands bouleversements économiques, sociaux, culturels voire spirituels l’ayant précédée dans l’histoire de l’humanité.
Il faut toutefois savoir raison garder quant à l’état actuel de ces technologies. L’IA est en ce moment – medias obligent – mise à toutes les sauces tandis que le moindre éditeur d’applicatif a très vite tendance à s’autoproclamer faiseur d’Intelligence Artificielle et à ajouter un « .ai » en fin d’adresse URL pour faire plus vrai.
Spécialisés dans la recherche appliquée en dialogue homme-machine, nous avons notre propre laboratoire de développement dédié à la compréhension du langage naturel, à la parole et surtout à ce qui la précède : la pensée.
InPrincipio vous apporte un éclairage de passionnés de l’IA sous un angle didactique et simple : ce qu’est l’Intelligence Artificielle, ce qu’elle n’est pas, comment elle fonctionne, quelles sont ses applications concrètes. Tout ce qu’il faut en savoir et juste ce qu’il faut en savoir.
L’humanité avance avec la science, son histoire s’écrit avec les progrès technologiques et les bouleversements qu’ils engendrent. L’intelligence Artificielle n’est plus un rêve, c’est aujourd’hui une réalité qui s’apprête à transformer le monde de demain. Cette révolution technologique attise des craintes, mais elle est inexorable.
Comprendre l’Intelligence Artificielle
L’Intelligence Artificielle est un ensemble de technologies numériques, mathématiques, statistiques et algorithmiques très évoluées qui permettent d’imiter ou d’étendre l’intelligence humaine à l’aide de machines capables d’apprendre, de « raisonner » et de prendre des décisions.
Ces technologies sont déployées dans des services, systèmes et applications et sont utilisées dans de nombreux domaines. On distingue l’IA forte de l’IA faible selon le niveau d’évolution de ces programmes informatiques.
L’IA faible ou descendante reproduit un comportement intelligent dans un domaine précis. La machine n’est pas capable de comprendre ses actions, mais elle peut apprendre et résoudre des problèmes.
L’IA forte ou ascendante se définit comme la pleine intelligence et la conscience de soi encore appelée Singularité. La machine serait capable d’analyser des situations, d’accomplir des actions rationnelles, d’avoir une conscience et de raisonner. Les recherches évoluent rapidement pour parvenir à ce stade d’évolution.
En savoir plus sur l’Intelligence Artificielle
L’Intelligence Artificielle d’hier Illustration et histoire
Le principe d’une Intelligence supérieure mécanique et non humaine est lointaine et pourrait remonter à l’Antiquité. L’Intelligence Artificielle commence à prendre forme dans l’ancienne Egypte et dans la Grèce antique, avec des instruments qui témoignent de son balbutiement.
Au fil des siècles, l’homme a essayé de créer des machines pour alléger ses tâches et pour accroître sa production. Du Moyen Age au XXe siècle, des artisans, savants et chercheurs vont imaginer des règles et des principes afin de concevoir des œuvres qui vont pousser l’IA dans les bras de à la réalité.
Les choses vont s’accélérer à partir des années 1950, avec l’article d’Alan Turing « Computing Machinery and Intelligence » et les travaux des pionniers John Mc Carthy, Marvin Minsky ou Allen Newell qui s’ensuivront. Les programmes intelligents connaissent un essor important dans les années 1970 jusqu’à l’avènement de l’internet au début des années 1990, et des moteurs de recherche sur le web à l’orée des années 2000 et enfin celui du Cloud et des processeurs ultra puissants.
En savoir plus sur l’histoire de l’IA
L’Intelligence Artificielle d’aujourd’hui
L’Intelligence Artificielle a atteint aujourd’hui un niveau d’évolution qui autorise son utilisation dans tous les domaines. Elle est devenue incontournable dans de nombreux systèmes destinés notamment à traiter les images et le langage, à réaliser des analyses prédictives, à diagnostiquer et à traiter certaines maladies graves, ainsi qu’à bien d’autres usages.
Les techniques s’améliorent progressivement au fil des ans pour donner des machines de plus en plus intelligentes. L’apprentissage automatique ou machine learning a succédé aux systèmes experts aujourd’hui dépassés. L’apprentissage profond ou deeplearning pousse la machine à plus d’autonomie et à plus d’intelligence.
Les géants de l’informatique et du web ne veulent pas rater ce tournant décisif de l’histoire de l’humanité. IBM, Google, Microsoft et bien d’autres acteurs ont pris la mesure des enjeux économiques et sociaux dont ils veulent être (ou rester) les fers de lance incontournables.
En savoir plus sur les usages, les techniques et les acteurs clés de l’Intelligence Artificielle
L’Intelligence Artificielle de demain Illustrations 1 et 2https://www.inprincipio.xyz/wp-cont...
Les recherches et applications business sur l’Intelligence Artificielle sont intenses, ce qui accélère les innovations et l’évolution des algorithmes intelligents. Les machines pourraient être capables dans quelques années d’avoir une conscience au sens propre du terme. Elles pourraient être conscientes de leur existence et manifester des aptitudes, ce qui se traduirait par l’émergence d’une l’IA forte comme l’ont rêvée de longue date les films de fiction hollywoodiens.
Cette évolution technologique suscite des inquiétudes sur les plans éthiques et moraux. L’IA met en jeu la vie privée avec l’exploitation des données composées en grande partie d’informations personnelles qui échappent aux particuliers.
On craint un taux de chômage record dans le monde, car les machines sont déjà aujourd’hui souvent plus performantes que les humains à presque tous les postes d’une entreprise. Et qu’en sera-t-il demain ?
Les politiques de défense militaire préfèrent engager le combat avec des machines armées plutôt qu’avec des hommes, avec toutes les dérives que cette – pourtant belle – option peut engendrer à terme. Des questions qu’on ne peut balayer d’un revers de la main s’agissant de l’IA du futur.
En savoir plus sur le futur de l’IA
le Blog sur l’Intelligence Artificielle
Pour plus d’ information >>> Nous contacter

INPRINCIPIO
Inprincipio est une traduction du grec « en archè èn o logos, kai o logos èn pros ton théon, kai théos èn o logos » où il est fait référence au « logos » : parole, discours, raison, relation, ces quatre mots formant les 4 principes de la technologie que bâtit In Principio. Copyright © 2018 - InPrincipio.xyz | Suivez-nous sur Twitter |Mentions légales
Copyright © 2018 - InPrincipio.xyz | Suivez-nous sur Twitter |Mentions légales
Source : https://www.inprincipio.xyz/
2.
L’Intelligence Artificielle expliquée aux humains – Par Henri Sanson - Jeudi 5 janvier 2017 - Blog de la recherche – Document ‘Orange Hello Future’ – Schéma explicatif simplifié
Plusieurs média ont déclaré 2016 Année de l’Intelligence Artificielle (IA dans la suite). Le sujet fait en effet le buzz, avec de nombreux articles, conférences, émissions qui lui sont consacrées.
Cet engouement fait suite à une séries d’annonces de progrès spectaculaires obtenus et surtout annoncés depuis environ 2 ans dans certains domaines, comme la reconnaissance faciale, la reconnaissance vocale, ou encore tout récemment le jeu de go (AlphaGo), principalement dues à l’utilisation d’algorithmes de Deep Learning, ou apprentissage neuronal profond, sur des grandes bases de données.
Ce qui frappe dans tout ce flot médiatique, c’est l’extrême diversité des solutions présentées comme relevant de l’IA, ce qui laisse à penser que l’IA ne constitue pas une unique technologie, mais un domaine technologique et scientifique traitant un vaste ensemble de questions différentes. Dans ce contexte, le but de cet article est de rappeler la définition de l’IA et d’en décrire les différentes facettes.
Définition et composantes de l’Intelligence Artificielle
L’intelligence Artificielle est un domaine vaste et pluridisciplinaire dont l’unité tient dans l’ambition initiale de faire reproduire par les machines des compétences cognitives qui sont normalement l’apanage de l’être humain : perception de l’environnement, représentation conceptuelle du monde, pensée, raisonnement, décision pour action.
De fait, l’IA est assez logiquement structurée en différents champs scientifiques traitant chacun une famille relativement homogène de problèmes et visant à mettre au point des solutions reproduisant, si possible en plus performantes, de telles compétences [1].
- le raisonnement constitue le cœur historique de l’IA. Il consiste à prédire des faits nouveaux à partir de règles ou de propriétés générales et de faits connus, donc de connaissances théoriques, et qui repose essentiellement sur les (langages) logiques mathématiques, mais également sur les probabilités pour prendre en compte l’incertitude inhérente aux connaissances dans certains domaines. Le raisonnement artificiel est basé sur l’exécution de moteurs d’inférence, c’est-à-dire de calcul logique sur des ensembles de connaissances formelles qui en constituent donc le carburant, les 2 aspects étant ainsi découplés.
Pour approfondir, voir [2][3][4]. >>> https://hellofuture.orange.com/app/uploads/2018/12/formes-de-raisonnement21-575x86.png
Les 4 types d’inférence
- la représentation des connaissances constitue le support au raisonnement, mais également à certaines approches de traitement automatique de la langue naturelle à des fins d’extraction d’information ciblée. Les modèles choisis pour représenter les connaissances varient selon le contexte. En ingénierie des connaissances et recherche d’information, on utilise les ontologies, pouvant revêtir des formes variées, depuis des thésaurus classiques de l’ingénierie documentaire, aux ontologies formelles retenues comme cadre par le W3C pour le Web Sémantique. Dans le domaine des systèmes dit « à base de connaissances », c’est-à-dire la version moderne des systèmes experts, on utilise plutôt la logique des prédicats du 1er ordre pour représenter des connaissances constituées de faits et des règles permettant de prendre aussi en compte des connaissances comportementales ou décisionnelles.
Voir un schéma explicatif
Représentation de connaissances sous forme ontologique (g) et en logique des prédicats du 1er ordre (d)
Les approches actuelles de production de telles connaissances formelles sont essentiellement manuelles, et se heurtent à des écueils de nature fondamentalement linguistique (synonymie, paraphrase, polysémie).
pour approfondir, voir [5][6][7][8].
- le traitement automatique de la langue naturelle (TALN) traite des grandes questions liées au langage humain : la production automatique de textes exprimant un sens donné, la compréhension automatique de la langue, la traduction. Le dialogue est parfois considéré comme relevant du TALN. Cependant, nous pensons plutôt qu’un agent dialoguant (conversationnel, chatbot) constitue une machine intelligente associant plusieurs composantes de l’IA, dont la planification (Dialog Planning). La compréhension automatique de la langue comprend l’analyse sémantique lexicale : signification des mots en contexte, l’analyse sémantique propositionnelle : extraction du sens de la phrase et l’analyse discursive : sens d’un énoncé ou discours multi-phrases.
L’extraction du sens lexical consiste, dans son principe, à rapprocher un mot ou plus généralement un terme (locution composée de plusieurs mots et désignant un concept) d’un référentiel sémantique lexical, de type ontologie ou thésaurus.
Une des approches phare en extraction du sens propositionnel est l’analyse en « cadres sémantiques » (Frames), consistant à identifier au sein d’une proposition (une phrase peut articuler plusieurs propositions), d’une part le prédicat pivot, et d’autre part les arguments de celui-ci ainsi que la sémantique de leurs rôles : en résumé, trouver qui a fait quoi, à qui, où, comment,…
Un exemple de frame sémantique
pour approfondir, voir [9][10][11].
- les technologies de reconnaissance sensorielle : reconnaissance visuelle, sonore, gestuelle, ainsi que de la parole (transcription),… La perception constitue la couche d’interface entre le monde extérieur et les centres de décision et de raisonnement au sein du cerveau. Les applications de la perception artificielle trouvent naturellement leur place dans l’Interaction Homme-Machine, l’indexation des contenus multimédia (photos, vidéo, audio) ou encore la sécurité (biométrie). C’était jusqu’à ce début d’année la discipline de l’IA qui avait connu les avancées les plus spectaculaire, grâce au Deep Learning, désormais rejointe par d’autres disciplines de l’IA.
Voir document explicatif
Deux exemples de perception des formes : la reconnaissance de concepts visuels (g) et la transcription de parole (d)
- Les fonctions décisionnelles, ou exécutives, dont le but est de permettre à des systèmes artificiels, les agents intelligents, de prendre des décisions d’actions.Des telles décisions peuvent être unitaires, isolées, comme par exemple décider d’une liste de films à proposer pour un système de recommandation, ou au contraire constituer des processus décisionnels c’est-à-dire des suites de décisions pour action at sur un système S pour atteindre un but donné (défini par une condition de fin Condf(st)) en visant un critère d’optimalité (récompense totale sur le long terme, appelée « utilité ») ou simplement en satisfaisant des contraintes d’exécution. Selon le contexte, la nature exacte des problèmes traités, mais surtout la communauté scientifique concernée, on parle de planification, contrôle automatique ou encore résolution de problèmes, qui recouvrent des réalités assez proches. De même, on désigne de tels processus décisionnels par les termes de plan, politique ou stratégie.
Voir un schéma explicatif
Formalisation générale d’un problème de planification / contrôle
pour approfondir, voir [12][13] [14][15].
- les systèmes multi-agents (SMA), modélisent une intelligence collective, à l’aide d’une collection d’agents intelligents, chacun mettant en œuvre chacun un processus décisionnel agissant sur une partie de l’environnement, en fonction de ses propres connaissances ou croyances locales, d’un intérêt personnel ou collectif, de manière coopérative, compétitive ou neutre. Il s’agit donc d’un processus de planification distribué, qui peut avoir des objectifs de pilotage optimal d’un système à l’instar d’une commande centralisée, mais peut également servir à simuler des organisations sociales de différentes natures : animales, humaines, artificielles,… Une application récente est par exemple la modélisation du marché du travail. On distingue d’une part les systèmes multi-agents rationnels où chaque agent cherche à maximiser son gain en anticipant sur les décisions des autres agents, et d’autre part les systèmes multi-agents réalistes, visant à reproduire au mieux des comportements réels.L’apprentissage multi-agents combine les modèles de la planification stochastique et de la théorie des jeux matriciels et consiste à entraîner un agent virtuel rationnel contre lui-même (self-play) pour déterminer des stratégies optimales, tandis que la simulation multi-agents réaliste vise à modéliser le comportement collectif réel d’une population animale ou humaine dans une situation donnée, par exemple en utilisant des modèles comportementaux individuels de type BDI (Belief, Desire, Intent).
pour approfondir, voir [16][17].
Modèle général d’un Système Multi-Agents
Les machines ou systèmes intelligents sont des assemblages de technologies issues de tout ou partie des précédents domaines, dans le but de constituer une solution applicative spécifique, telle qu’un assistant virtuel personnel (Siri, Viv, Google Assistant, Cortana,…), un véhicule autonome, un système de gestion de contenu, un réseau télécom cognitif…
Les deux grandes familles d’Intelligence Artificielle
Il est coutume dans les structurations académiques de l’IA de distinguer une IA anthropomorphique visant à imiter le fonctionnement de l’intelligence humaine, et recouvrant essentiellement la reconnaissance des formes sensorielles et le traitement du langage, et une IA rationnelle, visant à la prise de décisions rationnelles, et recouvrant essentiellement les fonctions décisionnelles et le raisonnement, voire les systèmes multi-agents. La nature et la finalité des tâches relevant de ces 2 grands courants met en évidence une autre dénomination possible de ces branches en distinguant
- Une Intelligence Artificielle d’Interface permettant un à un agent intelligent de s’interfacer et communiquer avec son environnement physique ou humain, et
- Une Intelligence Artificielle Décisionnelle qui décide des actions à effectuer sur cet environnement. Sur le plan méthodologique, la 1ère branche est aujourd’hui largement dominée par les approches neuro-inspirées de l’apprentissage neuronal profond (Deep Learning), tandis que la 2nde fait largement appel aux outils mathématiques décisionnels, tels que les logiques, l’apprentissage machine et le raisonnement probabilistes, la recherche opérationnelle ou la théorie des jeux. De ce fait, cette dernière branche englobe les méthodes décisionnelles du Big Data (data analytics, data mining,…) qui consistent à appliquer les outils d’apprentissage machine sur de grands gisements de données pour en extraire de la connaissance et prendre des décisions statistiquement optimales.
Cet article vient du Blog de la Recherche - Domaines de recherche : Données et connaissance
En savoir plus :
- Introduction à l’IA : définitions, genèse, domaines, représentation des connaissances et langages dédiés, Fabrice Lauri, cours de l’Université Technologique de Belfort-Montbéliard, 2009.
- Systèmes à base de connaissances : une introduction, Alain Mille, LIRIS, 2007-2011
- Architecture des systèmes à base de connaissances et introduction à Prolog, Fabrice Lauri, cours de l’Université Technologique de Belfort-Montbéliard, 2009.
- Approche Agent en Intelligence Artificielle – Raisonnement probabiliste, B. Chaib-draa, cours de l’Université Laval.
- Tutoriel SPARQL.
- Ingénierie ontologique, concepts, méthodes et outils, Gilles Kassel.
- W3C/Semantic Web
- The unreasonable effectiveness of data, Alon Halevy, Peter Norvig and Fernando Pereira, in IEEE Intelligent Systems, 2009.
- Notion de base en lexicologie, Alain Polguère, Observatoire de Linguistique Sens-Texte (OLST), Université de Montréal, 2001.
- Introduction au TALN et à l’ingénierie linguistique, I. Tellier, cours de l’université de Lille3, 2007
- Dépendances syntaxiques de surface pour le français, Marie Candito, Benoît Crabbé, Mathieu Falco, Oct. 2009.
- Approche Agent en Intelligence Artificielle – Note de cours, B. Chaib-draa, cours de l’Université Laval.
- Apprentissage par renforcement, Bruno Bouzi, septembre 2014
- Reinforcement learning, Florentin Woergoetter and Bernd Porr, Scholarpedia,
- Le vieillissement des fonctions cognitives, Cécile Cimetière et Sophie Schumm, Hopital Charles Foix, Ivry sur Seine.
- Modélisation et simulation multi-agents – cours 1 – prolégomènes, Jean-Daniel Kant, LIP6, cours de l’Université Pierre et Marie Curie.
- Apprentissage multi-agent, Marc-Olivier LaBarre, Département d’Informatique et de recherche opérationnelle, Université de Montréal.
Hello Future, vision du futur et innovations – Orange -Hello Future Newsletter > Suivez toutes les avancées en matière de recherche et d’innovation. S’inscrire

Résultat de recherche d’images pour ’Hello Future orange logo’
Source : https://hellofuture.orange.com/app/uploads/2018/12/IA-db1198x500.jpg
3.
Comment l’IA devient-elle un artiste ? - 2018 - Document ‘inprincipio.xyz/artiste/’
L’Intelligence Artificielle se déploie dans l’art pour se mesurer aux plus grands artistes du monde. Cet usage s’accroît aujourd’hui dans ce domaine et permet de réaliser des œuvres inédites. Composer de la musique avec des sons mélodieux et des rythmes originaux, dessiner de somptueux tableaux, imaginer des histoires alléchantes et déroutantes seront bientôt autant d’exploits à l’actif de l’Intelligence Artificielle car le progrès est à cet égard en marche.
Modèle génératif et création artistique de l’IA
Qu’est ce qu’un modèle génératif ?
Le mot provient du latin « Generativus » qui signifie « qui produit », « qui engendre ». Le Modèle Génératif est donc par définition Créatif donc artistique. En d’autres termes, l’intelligence artificielle serait en mesure de créer, comme l’homme mais cette fois à partir d’algorithmes donc numériquement.
Ces œuvres sont créées pour ainsi dire ex-nihilo sans être induites ou déterminées à l’avance quoi qu’inspirées par des exemples (comme pour les êtres humains…). Elles sont donc potentiellement aussi bien chorégraphiques que littéraires, musicales, ou graphiques.
Les modèles génératifs ont de nombreuses applications à court terme. Mais à long terme, ils peuvent apprendre automatiquement les caractéristiques naturelles d’un ensemble de données, que ce soit des catégories, des dimensions ou autre.
Autrement dit, un système intelligent est capable de produire une création en s’inspirant des caractéristiques clefs dont on l’aura nourri : j’apprends la musique à une machine dans le style de Beethoven et elle saura en extraire les caractéristiques pour écrire de la musique comme Beethoven…
Illustration musicale- Illustration en peinture
L’art génératif
L’art génératif est une création numérique qui s’appuie sur des algorithmes pour produire des œuvres artistiques qui s’auto-génèrent ou qui sont non définies à l’avance.Un algorithme graphique peut par exemple générer des œuvres presque comparables à celles de Picasso ou Léonard de Vinci. La machine est capable d’apprendre le style d’un artiste en analysant ses œuvres grâce au deep learning. La seule limite est celle du volume d’exemples dont on peut nourrir en entrée la machine mais elle va tout de même apprendre en en extrayant les principales caractéristiques.
Des programmes d’IA dans l’Art :
Orb Composer de Hexachords
Hexachords, la startup de Toulouse spécialisée dans l’intelligence artificielle pour la musique, a lancé Orb Composer, un système expert pour assister les compositeurs de musique dans leur création. Sa technologie est conçue avec de la musique orchestrale et compose des morceaux à partir des propriétés de 1 000 instruments/articulations. On va donc bien plus loin ici que le système d’arrangeur automatique qui existe depuis près de 20 ans : la machine n’orchestre plus seulement en fonction de l’harmonie définie par le compositeur, elle co-compose elle-même. Illustration
Daddy’s Car de Flow machine
Flow Machines conçoit des algorithmes de pointe pour explorer de nouvelles méthodes pour produire de la musique. L’entreprise recherche et développe des systèmes d’Intelligence Artificielle capables de générer de la musique de façon autonome ou en collaboration avec des artistes. Sa technologie peut transformer un ou de nombreux styles musicaux en un objet de calcul. Après ses recherches, la société a pu créer la première chanson pop d’IA structurée baptisée Daddy’s Car. Pour ce faire, la machine a digéré des tonnes d’exemples de musique avec un focus tout particulier sur la musique des Beatles. Le titre ressemble au final à s’y méprendre à une chanson écrite par John Lennon et Paul Mc Cartney quoi que chantée par un véritable humain au final. Daddy’s Car de Flow Machine Vidéo 3:00 animation visuelle en couleurs et musique accessible à la source.
Google deepdream
DeepDream est un programme d’intelligence artificielle et de vision par ordinateur créé par Google. Cette technologie utilise un réseau neuronal convolutif pour trouver et renforcer des structures dans des images. Les paréidolies créées par l’algorithme leur donnent une apparence hallucinogène. Le réseau de neurones artificiels a été entraîné à reconnaître des formes sur des images. La machine peut apprendre à les classifier à partir des millions d’images que les chercheurs y ont fait entrer puis à les injecter dans des créations fantasmagoriques. L’ordinateur s’amuse, comme un humain, à repérer une forme d’animal dans la forme d’un nuage. Si la machine voit une forme ressemblant à un escargot dans les feuillages d’un arbre, il va modifier l’image de base pour y insérer un escargot.
Exemples d’images – Voir par exemple ceci
Decibel Illustration
Decibel Music Systems, aujourd’hui appelée Quantone, est une société de logiciels de musique intelligence qui propose aux développeurs et aux entreprises de médias des métadonnées riches de la musique. Elle utilise une technologie qui collecte et stocke des données connectées sur les artistes et leurs œuvres, ainsi que sur les relations qui lient les artistes. Les informations compilées portent également sur les producteurs, les ingénieurs, les musiciens de session, le droit d’auteur et d’autres données. En 2015, la société a annoncé une collaboration avec Watson, la plateforme d’informatique cognitive d’IBM.
Musicgeek
MusicGeek est une solution unique développée en partenariat avec IBM Watson, capable de combiner l’opinion d’experts avec des métadonnées de profondeur grâce à l’utilisation de l’informatique cognitive.
Niland Illustration
Niland est une Start up qui développe des technologies basées sur le machine learning pour les musiciens et entreprises du secteur de la musique. Elle conçoit des applications d’IA capables de comprendre la musique. Ses algorithmes analysent le contenu audio, apprennent et se renforcent. Ils extraient des informations significatives des pistes pour les transformer en données décisionnelles. Ils peuvent également capturer automatiquement les caractéristiques musicales et émotionnelles directement à partir du signal audio.
D’autres articles sur le même thème qui vont vous intéresser :
L’IA et le traitement d’images et de vidéos Le traitement de l’image et de la vidéo est un des principaux usages de l’IA.
L’IA et les applications liées au langage Le traitement du langage est un domaine de l’IA qui regroupe les programmes de reconnaissance vocale ou de la parole
L’analyse prédictive Le terme d’analyse prédictive (ou encore logique prédictive) un des usages de l’IA faisant appel à des technologies
L’IA et les jeux Les chercheurs se sont très vite intéressés à l’usage des techniques de l’Intelligence Artificielle dans la programmation
L’automatisation et l’IA L’usage de l’intelligence artificielle (IA) ne concerne pas uniquement les activités quotidiennes et l’expérience utilisateur final des nouvelles technologies.
La robotique humanoïde L’Intelligence Artificielle s’adapte à tous les domaines. L’IA se déploie dans presque tous les secteurs d’activité,
L’IA et les biotechnologies L’usage de l’Intelligence Artificielle dans le domaine de la santé est en forte croissance.
La simulation des systèmes complexes La simulation d’un système complexe permet de reproduire et d’observer des phénomènes complexes (biologiques, sociaux et autres) pour les comprendre et anticiper leur évolution.
Pour plus d’information, n’hésitez pas à nous contacter : Nous contacter
Intelligence Artificielle pour les débutants avec inprincipio.xyzhttps://www.inprincipio.xyz
« La démocratisation des technologies d’Intelligence Artificielle et à ses applications business concrètes mais vise surtout à terme à devenir la première entreprise parvenant à créer une véritable intelligence de synthèse en modélisant le système cognitif du cerveau humain. In Principio est un laboratoire de recherche fondamentale en Compréhension du Langage Naturel (CLN). Sa mission : « Grow the most intelligent machine ever ».
« Nos laboratoires sont basés en Ile de France et en Haute-Savoie et travaillent au quotidien à la création d’une architecture d’IA révolutionnaire et Made in France.
In Principio allie en son sein un très haut niveau de technicité et une approche business obsessionnelle. Cet ADN lui vient des profils extrêmement complémentaires de ses deux associés fondateurs passionnés d’IA :
- Gilles Dumont d’Ayot, consultant en Intelligence Artificielle, ingénieur et Docteur en IA (Institut National des Sciences Appliquées de Toulouse)
- Alexandre Barillet, diplômé de l’Ecole Supérieure de Commerce de Paris, Directeur du Business Développement au sein du groupe Casino puis Carrefour, speaker vulgarisateur en Intelligence Artificielle
In Principio a fait sciemment le choix déterminant de ne pas développer sa technologie sur les bases du très à la mode machine-learning considérant que, quoi que révolutionnaire dans la reconnaissance d’images, ce procédé ne saurait s’appliquer parfaitement à la modélisation de la pensée humaine.
Non, In Principio a au contraire fait le choix ambitieux du développement ex-nihilo d’une technologie 100% nouvelle mariant l’ensemble des connaissances en matière de sciences cognitives et de traitement du langage naturel : représentation et structuration des connaissances, modélisation des raisonnements, linguistique, réseaux de concepts, apprentissage, algorithmes, etc…afin que notre machine soit à même de comprendre et de développer à terme des mécanismes de véritable pensée, loin des boîtes noires traditionnelles de la statistique.
In Principio, dont la mission est de tenter de modéliser l’intelligence première et profonde, signifie en latin « au commencement » en référence au Prologue de l’Evangile selon Saint Jean (1:1) : « Au commencement était le Verbe, et le Verbe était en Dieu, et le Verbe était Dieu. Il était au commencement en Dieu.
Tout par lui a été fait, et sans lui n’a été fait rien de ce qui existe.
En lui était la vie, et la vie était la lumière des hommes, etc… »
INPRINCIPIO
Inprincipio est une traduction du grec « en archè èn o logos, kai o logos èn pros ton théon, kai théos èn o logos » où il est fait référence au « logos » : parole, discours, raison, relation, ces quatre mots formant les 4 principes de la technologie que bâtit In Principio. Copyright © 2018 - InPrincipio.xyz | Suivez-nous sur Twitter |Mentions légales
Source : https://www.inprincipio.xyz/artiste/
Autres suggestions d’ Inprincipio
Le blog sur l’actualité de l’intelligence artificielle par In Principiohttps://www.inprincipio.xyz › blog › page
Intelligence Artificielle pour les débutants avec inprincipio.xyzhttps://www.inprincipio.xyz
L’intelligence artificielle fortehttps://www.inprincipio.xyz › ia-forte
4.
Google Deep Dream – Une IA capable de créer des œuvres d’art Par Bastien Lavril 3, 2017 Intelligence Artificielle Commentaires fermés sur Google Deep Dream – Une IA capable de créer des œuvres d’art
L’équipe Google Brain a développé Google Deep Dream, un algorithme de Machine Learning capable de réaliser des œuvres d’art. Ses créations sont tout bonnement fascinantes.
L’algorithme Google Deep Dream a appris à identifier des objets en scannant des millions de photos pixel après pixel. Le programme a d’abord appris à distinguer les différentes couleurs et leurs nuances, puis à identifier les bordures entre les objets. Au fil du temps, Deep Dream a appris à séparer un objet d’un autre et a développé un catalogue regroupant chaque objet de chaque image qu’il a scanné.
Par la suite, l’algorithme a compris comment arranger et catégoriser les objets dotés de caractéristiques similaires, et a appris comment recréer des composantes aléatoires de ces objets. Enfin, à la demande de ses créateurs, le programme s’est employé à disposer un ensemble aléatoire de ces images sur un template de paysage.
Google Deep Dream repousse les limites de l’intelligence artificielle
Image - Il y a encore peu de temps, l’art était considéré comme la dernière limite de l’intelligence artificielle. En contemplant les images réalisées par cette IA, force est de constater que cette barrière est sur le point de tomber à son tour.
Une fois que l’algorithme est assemblé, il suffit de quelques semaines, quelques heures ou quelques minutes, selon la technique à employer, pour maîtriser des compétences qui peuvent prendre une vie entière pour être acquises par l’être humain.
Art IA et propriété : à qui appartiennent les œuvres créées par l’intelligence artificielle ?
Image - On peut toutefois s’interroger sur la propriété de ces images. Légalement, une personne peut se déclarer propriétaire d’une chose qu’elle dessine, crée ou produit. Cependant, en l’occurrence, il s’agit d’une œuvre dessinée par un programme créé par l’Homme. Pour l’heure, cette interrogation peut sembler secondaire.
Cependant, lorsqu’une intelligence artificielle sera en mesure de développer des logiciels, de rédiger des articles, ou de créer des outils de diagnostic, il sera nécessaire de réellement se pencher sur cette question.
Si les personnes qui écrivent le code d’une intelligence artificielle détiennent également ce que cette IA crée, les géants de la tech comme Google seront en mesure de créer une IA ou d’avoir suffisamment d’IA différentes pour faire tout ce qu’un être humain peut faire en mieux. Ces entreprises détiendront alors le monde entier, au sens propre du terme.
AI Experiments, un site web pour contribuer au soulèvement des machines
Illustration - Google développe une variété d’outils pour aider à accélérer l’apprentissage des IA de Machine Learning. Le dernier de ces outils est intitulé AI Experiments. Ce site internet propose à l’utilisateur de joueur avec un assortiment de programmes reposant sur différentes techniques de Machine Learning.
Prenez garde : tout en se divertissant, le visiteur de ce site aide les machines à devenir plus intelligentes. Par conséquent, vous serez éventuellement coupables le jour où l’intelligence artificielle se soulèvera contre l’humanité, ou le jour ou Google deviendra le maître du monde.
Autres articles dans ce genre :
Google DeepMind trouve la sortie d’un labyrinthe plus vite qu’un humain mai 10, 2018
Stephen Hawking craignait que l’intelligence artificielle éradique la race humaine mars 14, 2018
OpenAI : une IA a appris à lire les sentiments sans qu’on lui demande mars 5, 2018
Tags Google - Powered by WordPress | Designed by TieLabs - © Copyright 2019, All Rights Reserved - Source : http://www.artificiel.net/google-deep-dream-0304
5.
Création artistique et intelligence artificielle : de l’art ou du cochon ? Par Alexandre Lourié - Directeur général Groupe SOS Culture, directeur général Scintillo - - Photo - Nov 19, 2017 - Ecrit avec mon ami Alexis Aulagnier, doctorant en sociologie à Sciences Po.- Document ‘medium.com/@louriealexandre’
Ce texte a été publié sous le titre « L’art : dernière frontière entre l’homme et l’intelligence artificielle, ou point de bascule ? » au sein du catalogue de l’exposition « La Belle Vie numérique ! », présentée par la Fondation Groupe EDF à Paris du 17 novembre 2017 au 18 mars 2018. Il est également paru dans Beaux Arts Magazine n°404 — février 2018.
A la rentrée 2017, le premier ministre a confié à Cédric Villani, médaillé Fields, désormais député, une mission visant à définir une stratégie nationale en matière d’intelligence artificielle (ou « IA »). Il est vrai que les questionnements autour de l’IA se multiplient. Outre-Atlantique, Elon Musk s’inquiète depuis plusieurs années déjà des « robots tueurs » et, plus encore, de l’indifférence des pouvoirs publics à leur sujet. Au point de lancer ses propres équipes de recherche sur le sujet, à travers ses deux sociétés OpenAI et Neuralink.
Si l’IA inquiète pour ses applications militaires et sanitaires, on questionne encore peu la place croissante qu’elle prend en matière de culture. Il existe pourtant des intelligences artificielles capables d’écrire des poèmes, de composer de la musique ou encore de peindre des tableaux. La création artistique semble, plus que jamais, à portée de programmes informatiques. En cela, la dernière frontière entre l’homme et la machine s’estompe. Car si l’IA est capable d’imaginer, de créer, mais aussi d’être sensible à l’art, qu’est-ce qui nous distingue, nous humbles humains, d’elle ?
L’art sépare l’humanité du reste du monde
Pour certains, il est impossible de distinguer les animaux des hommes (voire des dieux) ; mais pour les plus cartésiens, les animaux ne sont que des « machines » dépourvues d’âme, de pensée, de faculté de se concevoir eux-mêmes. Au-delà de ces débats, l’art constitue une frontière solide entre l’homme et le reste du monde, et partir de cette différence fondamentale permet d’interroger ce qui est propre à l’espèce humaine.
Dans Réflexions sur la vie créatrice, le commentaire que Bernard Grasset offre aux Lettres à un jeune poète de Rilke, la création est posée comme manifestation suprême de l’humanité : « créer, c’est l’acte même de la vie, son affirmation, sa contrainte, ou mieux c’est la puissance que la nature confia à toute vie, pour la réalisation de ses plans éternels. Nous ne saurions donc ici séparer l’instinct qui porte notre être physique à transmettre la vie et le besoin de notre personne de s’affirmer par ses créations. » Grasset écrit en référence directe à Rilke, pour qui la création est indissociable de la nature physique de l’homme : « qu’elle soit de la chair ou de l’esprit, la fécondité est une, car l’œuvre de l’esprit procède de l’œuvre de chair et partage sa nature. Elle n’est que la reproduction en quelque sorte plus mystérieuse, plus pleine d’extase, plus éternelle de l’œuvre charnelle. »
En somme, l’art est l’ultime expression humaine. Interroger la création artistique, c’est interroger l’homme. Interroger les créations de l’IA, c’est interroger ce qui nous sépare d’elle, ou ce qui nous en rapproche.
L’intelligence artificielle, prochain Michel-Ange ?
Il devient difficile de distinguer les œuvres produites par des êtres humains des productions de l’IA. Les peintures de Google ont fait le tour du monde. Elles sont issues des technologies de deep learning, méthode d’apprentissage automatique à partir de l’absorption massive de données. En d’autres termes, elles puisent dans la diversité visuelle du monde — du moins celle que l’on retrouve sur internet — pour imaginer de nouvelles formes d’expression. La technique porte même un nom : l’inceptionnisme.
Illustration en couleurs - Une oeuvre de l’IA de Google développée par Deep Dream.
De manière plus classique, l’expérience The Next Rembrandt, conduite en 2016 par Microsoft, a consisté à entraîner une machine à peindre comme le maître hollandais. Au point de façonner l’épaisseur des coûts de pinceau à l’aide d’une imprimante 3D. La qualité de la création a pu tromper l’œil le plus exercé. Quelle vertigineuse prise de conscience : la peinture du robot provoque une émotion comparable à celle de l’artiste.
L’IA peut aussi se faire poète. Nourrie par plus de 10.000 manuscrits non publiés, une intelligence artificielle s’est essayée à la rédaction de textes déroutants. En partant de citations réelles, le programme a appris à rédiger de courts paragraphes, dans les limites de sa base de données.
there is no one else in the world.
there is no one else in sight.
they were the only ones who mattered.
they were the only ones left.
Les progrès de l’intelligence artificielle sont plus saisissants encore en matière de création musicale. De nombreuses startups s’attaquent déjà à ce marché et les programmes capables de fabriquer des chansons se multiplient. Chaque jour charrie son lot d’exemples plus ou moins convaincants.
Musique – Vidéo 3:03 - Le dernier en date est celui de l’album « I am IA » de Taryn Southern intégralement composé par une IA.
Devant ces avancées, le premier débat qui émerge n’est pas celui de la frontière entre la machine et l’homme. C’est celui de l’argent : qui détient les droits d’auteur ? A ce titre, le tout premier article du code de la propriété intellectuelle dispose que, pour bénéficier d’une protection au titre des droits d’auteur, une œuvre doit être une « œuvre de l’esprit ».
La même interrogation avait opposé l’humain à l’animal dans la désopilante « affaire Naruto ». Un macaque avait volé l’appareil d’un photographe pour se prendre en selfie. Il a fallu qu’un juge de San Francisco se prononce en faveur de David Slater, le malheureux photographe, pour affirmer que le droit d’auteur est bel et bien humain, privant le singe Naruto de ses royalties.
A l’instar de Naruto, l’intelligence artificielle se définit en opposition à l’humain sur la question des droits d’auteur : peut-elle être considérée en tant que « créateur » ? C’est en tout cas le pari de la chanteuse Taryn Southern qui, pour susciter le débat, a décidé de rémunérer le programme Amper ayant fabriqué ses musiques.
L’exemple du film de réalité virtuelle « Altération » est plus sophistiqué encore. Les pionniers français des œuvres immersives, Okio studio, ont collaboré avec les équipes de l’intelligence artificielle de Facebook pour générer des effets spéciaux. Leur IA s’est entraînée à partir des œuvres d’un artiste français pour créer des formes visuelles interactives. Il n’est guère surprenant que ce nouveau procédé de création soit en premier lieu exploré par les nouvelles formes d’art en réalité virtuelle.
L’IA de Disney pousse le débat encore plus loin : si l’intelligence artificielle crée, elle devient également capable d’apprécier la création. Pour évaluer la qualité d’un certain nombre de fictions, ce robot est devenu une référence plus fiable que les humains eux-mêmes. Il en va de même en matière d’humour : une étuded’Harvard a démontré qu’une IA prédit les blaguesqui vous feront rire avec plus de succès que votre conjoint ou votre meilleur ami. Vous êtes prévenus…
L’IA, rien de plus qu’un outil ?
Ces exemples sont fascinants, mais l’IA ne s’y comporte jamais autrement que comme un algorithme. C’est un outil aujourd’hui incapable de s’affranchir : l’homme est celui qui produit les œuvres qu’elle « digère » ; il est celui qui conçoit la procédure transformant les inputs en outputs, bien que les capacités d’auto-apprentissage des machines se sophistiquent ; et l’IA ne repose jamais que sur des composants physiques produits par l’homme (processeurs, disques-durs, réseaux, etc.).
Cela sépare l’IA de la création strictement humaine pour trois raisons : elle ne peut pas ressentir ; elle n’est pas dotée « d’élan créateur » ni de subjectivité ; elle n’a pas la faculté d’effectuer le pas de côté essentiel à la création.
Premièrement, pour créer, il faut ressentir. Si l’on nourrit les intelligences artificielles à partir d’œuvres d’art consacrées comme telles, la faculté de création de l’homme se nourrit aussi de sa capacité de s’émouvoir de l’ensemble du monde sensible, à l’inclusion d’objets non artistiques. C’est ce dont se montre capable André Breton dans la première partie de Nadja, où il présente sa collection intime du sensible. Il évoque Chirico, Courbet, Apollinaire et Huysmans, mais il parle, avec la même exigence, d’expériences sensibles de l’ordinaire : les panneaux « BOIS-CHARBONS » que l’on trouvait sur toutes les bonnes épiceries ou encore un mystérieux demi-cylindre blanc acheté au marché aux puces de Saint-Ouen.
Illustration - Demi-cylindre blanc acheté par André Breton au marché aux puces de Saint Ouen, correspondant à la statistique établie dans les trois dimensions de la population d’une ville de telle à telle année « ce qui pour cela ne [la] rend pas plus lisible »
Si Breton est capable d’un tel inventaire, c’est qu’un élan intérieur l’amène à sélectionner de manière imprévisible les items qui contribuent et construisent sa créativité. Ses sens ne sont pas de simples capteurs : à la différence d’une IA, sa perception du monde n’est pas prisonnière d’un système autre que son corps.
Deuxièmement, l’artiste répond à une nécessité de créer et celle-ci ne se programme pas. Ce n’est pas la « nécessité d’écrire » qui pousse une IA à composer de la poésie. A contrario, lorsque Fernando Pessoa noircit trente mille feuilles de poèmes, il répond à un besoin impérieux d’exprimer sa subjectivité : « ce à quoi j’assiste est un spectacle sur une autre scène. Ce à quoi j’assiste, c’est moi. Mon Dieu, à qui suis-je en train d’assister ? Combien suis-je ? Qui est moi ? Quel est cet intervalle qui se glisse entre moi et moi ». Et pour preuve, il ne destinait pas ses œuvres à un autre destin que celui de prendre la poussière dans une malle découverte après sa mort.
Troisièmement, la création nécessite un pas de côté. Quand Eluard dit que « la terre est bleue comme une orange », il ment, mais c’est pour dire la vérité. Le reste du monde, robots inclus, ne possède pas cette aptitude. Aucun algorithme n’est soumis au besoin de transcender son système pour s’exprimer. De toute manière, aucun n’en a la possibilité.
De nombreux tests ont été élaborés pour définir la différence entre l’homme et la machine. Le test de Turing, par exemple, consiste à demander à un cobaye humain de déterminer s’il dialogue avec un autre être humain ou une machine. Ce test n’apprend en réalité pas grand-chose : il est de plus en plus facile pour les intelligences artificielles de cacher leur nature. Comme le montre le projet The Next Rembrandt, nous sommes aujourd’hui incapables de distinguer la production d’un algorithme de celle d’un peintre.
L’enjeu se situe désormais au niveau d’un test plus sophistiqué, « la chambre chinoise », qui a été imaginé par John Searle en 1980 précisément en dépassement du test de Turing. Dans cette expérience, un homme enfermé dans une pièce communique avec l’extérieur au moyen de caractères chinois, quand bien même il n’a aucune notion dans cette langue. A l’aide d’un catalogue de règles permettant de répondre à des phrases en sinogrammes, cet homme est en mesure de dialoguer sans pour autant comprendre ses propres propos. Si l’on traduit cela en matière d’intelligence artificielle, on en conclut que la faculté de la machine à tromper un être humain ne dénote pas de l’apparition d’une conscience ou d’une capacité de création. En l’absence de conscience, l’IA ne dépasse pas le stade de la reproduction.
Singularité ou augmentation de l’homme
Le dualisme cartésien est confronté aujourd’hui à une interrogation nouvelle. L’intelligence artificielle parviendra-t-elle un jour à s’affranchir de l’homme en gagnant ce qui est sa qualité propre : l’esprit ?
Deux écoles émergent quant à l’avenir de l’IA. Les plus cartésiens considèrent qu’elle ne sera jamais qu’un outil, certes très sophistiqué, au service de l’homme. Dans ce cas, si les progrès en matière d’interface cerveau-machine offrent à l’être humain une extension de sa conscience et de ses capacités, l’IA ne sera jamais qu’une technique au service de sa création, comme les contraintes de l’Oulipo en leur temps. Rappelons également que le processus d’apprentissage de l’IA, le machine learning, n’a rien à voir avec celui de l’humain : à la différence du robot, je reconnais un chat car je lui accorde un sens, pas parce que j’en ai déjà vu mille. Cela étant dit, l’exploration des terres vierges de la création artistique par un Homo Deus armé de l’IA révélera à coup sûr des formes d’expression que l’on peine à imaginer aujourd’hui.
Dans l’autre camp, les « futurologues » de la Silicon Valley tels que Nick Bostrom, Serge Kurzweil ou Elon Musk, théorisent déjà une nouvelle forme de conscience : la « singularité ». Ils se gardent de tout anthropocentrisme pour admettre qu’il s’agira d’un esprit de type inconnu dont il est impossible d’imaginer la sensibilité. Nous sommes bien incapables d’imaginer ces nouvelles formes de création et, pire, de savoir si nous serons seulement en mesure de percevoir ces émotions d’un nouveau type.
Si cela advient, l’expérience de la « chambre chinoise » sera inversée : l’homme sera à son tour incapable de comprendre véritablement les expressions, artistiques ou non, de la machine.
AI Intelligence Artificielle Création Artistique Art Singularity

Résultat de recherche d’images pour ’medium.com logo wikipédia’
6.
Un tableau réalisé par une intelligence artificielle aux enchères, chez Christie’s
Paris Match | Publié le 25/09/2018 à 17h44 |Mis à jour le 26/09/2018 à 07h06 - Romain Clergeat - Toute reproduction interdite – Vidéo 0:58
7.
L’intelligence artificielle fait son trou dans le marché de l’art Par François Manens | 06/03/2019, 17:14 – Document ‘latribune.fr’ - Illustration - ’Memories of Passersby I’ de Mario Klingemann s’est vendu à 40.000 livres. (Crédits : Mario Klingemann) - L’artiste Mario Klingemann a vendu pour 46.500 euros une oeuvre qui diffuse sur deux écrans des portraits générés par une intelligence artificielle. Cette deuxième incursion de l’IA dans l’art marque l’ouverture du marché au code créatif.
Pour 40.000 livres (46.500 euros), un internaute anonyme a acquis l’installation Memories of Passersby 1 de Mario Klingemann. L’oeuvre est composée de deux écrans 4K, reliés par des câbles à du matériel informatique logé dans un meuble en châtaignier. Sur les deux écrans défilent en continu des portraits, plutôt masculins pour l’un, plutôt féminins pour l’autre. Ces visages sont générés de façon unique et en temps réel par les réseaux neuronaux de la machine. Un peu plus de 4 mois après la première vente d’une œuvre générée par une intelligence artificielle, écoulée à plus de 400.000 dollars, Mario Klingemann propose une autre vision des possibilités artistiques permises par la technologie, et ouvre un nouveau volet du marché de l’art.
432.500 dollars pour la première vente en octobre 2018
Le marché de l’art contemporain s’élevait en 2018 à 1,9 milliards de dollars, avec un prix moyen de 28.000 dollars par oeuvre, d’après Art Price. Pourtant de plus en plus reconnu, le milieu du code créatif, dont Mario Klingemann est une des figures, ne prend pas encore sa part du gâteau. Depuis près de 15 ans, l’artiste allemand expose son travail, au MOMA et au MET à New York, ou encore au Centre Georges Pompidou à Paris, mais son travail ne s’était jamais vendu aux enchères. Il fait de nouveau figure de précurseur avec cette vente à 40.000 dollars (la tranche haute de l’estimation), opérée à Londres par Sothebys.
La première vente d’une oeuvre sur la base d’un code créatif a eu lieu en octobre 2018. Le collectif parisien Obvious avait présentée une peinture générée par une intelligence artificielle, ou plus exactement, par des réseaux antagonistes génératifs (GAN, en anglais). Au coin du portrait de Edmond De Bellamy, ses créateurs avaient signé d’une formule mathématique, celle de l’algorithme. Estimée à 8.000 dollars par Christie’s, l’oeuvre présentée comme ’générée par une intelligence artificielle’ s’était vendue à 432.500 dollars.’C’est la folie du marché de l’art’ avait balayé Mario Klingemann, interrogé par le public du GROW festival de Paris. La formule utilisée était disponible en open source sur GitHub depuis plusieurs années, et avait simplement été mise en application puis imprimée. Ensuite, la communication et le récit autour de cette première avaient fait grimper les enchères.
Memomies of Passersby, une prouesse technologique
La différence est que Memories of Passersby 1 n’utilise non pas un, mais six GAN. Un GAN se compose de deux modules, qui œuvrent en parallèle. Le générateur crée des images similaires aux données fournies par l’artiste. Pour cette installation, Klingemann a nourri sa machine de portraits du 17ème, 18ème et 19ème siècles, peints par de grands maîtres. Le second module, le ’discriminateur’, recale les images trop proches du matériel original. Le système s’améliore grâce à ces interactions, et génère des images uniques. A partir de cette méthode, le résident de Google Arts et Culture a développé de nouveaux algorithmes. Par exemple, il peut mettre les résultats d’un GAN comme matériau de base d’un autre GAN, ou introduire une erreur volontaire dans le code. Certains trouveront un intérêt esthétique à l’oeuvre, et d’autres apprécieront également le travail technique du développeur.
’Ce n’est pas facile de créer une image aussi grande, affichable en 4K, et c’est compliqué de les faire générer à cette vitesse. Sans vouloir me vanter, je ne connais pas beaucoup d’autres artistes qui pourraient aujourd’hui faire la même chose.’ précise Mario Klingemann
L’installation générera de nouveaux portraits uniques de personnes qui n’existent pas, à chaque seconde, et jusqu’à ce que la machine tombe en panne. Ne comptez cependant pas sur Klingemann pour dire que l’intelligence artificielle est l’auteur de son oeuvre. Avec un argument imparable : ’est-ce que vous demanderiez à un pianiste si son piano est l’auteur de la pièce ?’
Sur le même sujet
’L’artiste, le robot et l’IA’ : vers une nouvelle définition de l...
Les robots seront-ils les artistes de demain ?
La Tribune https://www.latribune.fr Abonnez-vous

Résultat de recherche d’images pour ’.latribune.fr’
8.
L’Intelligence artificielle au service de l’art - Lundi 11 février 2019 – Document ‘/hellofuture.orange.com/’ -Photo
De la création à l’estimation des œuvres, en passant par la reproduction, l’IA s’immisce dans de nombreuses activités liées à l’art. L’art n’échappe pas au raz-de-marée de l’intelligence artificielle. De la création à l’estimation des œuvres, en passant par la reproduction, l’IA s’immisce dans de nombreuses activités liées à l’art. Ainsi, des algorithmes sont aujourd’hui capables d’écrire des poèmes, de composer de la musique ou encore de peindre des tableaux.
1. L’IA au service de la création
Trois Français du collectif Obvious ont créé une peinture représentant le portrait d’un homme du XVIIIe siècle. Réalisée par un algorithme, cette œuvre est issue de l’identification des traits communs au sein de 15 000 portraits des XIVe et XXe siècles. Une peinture vendue aux enchères le 25 octobre dernier chez Christie’s à New York pour la bagatelle de 432 500 $ ! – Reproduction.
Autres exemples, les peintures de Google issues des technologies de deep learning et de la diversité visuelle du monde puisées sur Internet. Citons aussi l’expérience The Next Rembrandt, conduite en 2016 par Microsoft, consistant à entraîner une machine à peindre comme le maître hollandais.
Reproduction - Pour la poésie, l’IA a utilisé plus de 10 000 manuscrits non publiés et le programme a appris à rédiger de courts paragraphes en partant de citations réelles.
En matière de scénario, la Century Fox et IBM ont conçu Morgan en utilisant un algorithme nourri par une centaine de bandes-annonces de films d’horreur. La machine n’a cependant pas tout créé : elle a simplement sélectionné des extraits du film méritant selon elle de figurer dans un trailer, et c’est un ingénieur d’IBM qui a réalisé ensuite le montage.
Autre exemple, l’algorithme Benjamin, développé par le réalisateur Oscar Sharp et le chercheur Ross Goodwin et nourri par des dizaines de scénarios de films et de séries de science-fiction, a créé le film Sunspring.
Voir une vidéo 3:27 (en anglais) à la source - Autre terrain de jeu de l’IA : la musique. De nombreuses start-up produisent des programmes informatiques capables de fabriquer des musiques. Exemple : Muzeek (anciennement iMuze), start-up cofondée par Alain Manoukian, qui permet de générer une musique correspondant aux critères de l’utilisateur : genre, durée, structure musicale, tempo, etc…
De son côté, Sony Computer Science Laboratory (CSL) a conçu l’algorithme Flow Machines, qui a composé une musique « s’inspirant » des Beatles des années 1960, soit en « digérant » 1 300 partitions tirées des morceaux des Beatles et de groupes proches afin de transposer ce « style » en calculs et de mieux le copier.
Citons aussi le denier album de Taryn Southern, I am IA, intégralement composé grâce à une IA.
Voir une vidéo 4:08 (en anglais puis en français) à la source
2. L’IA au service de l’expertise
L’IA est par exemple efficace pour expertiser la signature d’une œuvre, sans remplacer l’expert, mais pour l’aider dans ses démarches. Certaines technologies comme les Generative Adversarial Networks (GAN) ou réseaux antagonistes génératifs, consistant à entraîner deux réseaux de neurones en parallèle (l’un génère des images et l’autre vérifie si ces images sont connues ou non), permettraient de reconnaître l’ensemble des caractéristiques du travail d’un artiste. Il deviendrait alors possible d’identifier la vraisemblance ou d’estimer la probabilité qu’une œuvre soit authentique.
3. L’IA au service de la restauration
L’IA peut être aussi utilisée dans la restauration des œuvres endommagées. À partir d’un fragment d’une œuvre, les réseaux neuronaux permettent de capter le style de l’artiste et de reproduire les fragments manquants de manière vraisemblable.
Conclusion - Mais attention, il ne s’agit que d’algorithmes, couplés à de l’apprentissage machine. À ce jour, l’IA ne peut reproduire toute la créativité d’un humain.
Mots-clés : art, Intelligence Artificielle, smart society, Start-up
Sur le même sujet
Intelligence Artificielle -Reconnaître et modifier vos caractéristiques faciales grâce à l’intelligence artificielle
ProspectivePodcast : L’IA dans l’émotion et au service de l’humain
Intelligence ArtificielleMWC 2019 : comment l’Intelligence Artificielle accélère le travail des analystes en cybersécurité
Hello FutureÀ propos EN- Hello Future Newsletter > Suivez toutes les avancées en matière de recherche et d’innovation. S’inscrire
Source : https://hellofuture.orange.com/fr/lintelligence-artificielle-au-service-de-lart/
9.
L’intelligence artificielle est-elle en train de devenir l’artiste de demain ? Article de Valentin Ginard – @valentinginard – 3ème année – Cycle Mastère en 3 ans. Document ‘ecvdigital.fr/ecole-digitale’ – Illustration : Can Artificial Intelligence Make Art ?
Aussi imaginaire que cela puisse paraître, l’intelligence artificielle n’est plus un fantasme ni même une fiction. De Black Mirror à Her ou encore Matrix, ces films et séries nous interrogent sur la définition même de l’intelligence et de la conscience. Et l’art n’y échappe pas. S’il est facile de s’amuser du cousinage étymologique de « artificiel », l’art et la culture sont des traits bien distinctifs qui constituent l’Humain. Aussi parfois est-il difficile d’envisager que l’AI pourrait nous retirer ce privilège.
L’une des questions fondamentales réside dans ce que véhicule l’art en nous : des émotions. Une œuvre artistique est alors issue de la créativité d’un artiste. On parle alors de capacité qu’a un individu à imaginer, réaliser, à créer quelque chose de nouveau.
Le débat se porte alors sur ce concept de « nouveau ». Imagination ? Inventivité ? Une machine est-elle capable de faire preuve de créativité ?
Création artificielle : entre émotions et simulations
L’année 2015 fut la période de l’art psychédélisme digital. Nos réseaux sociaux fleurissaient d’images étranges, presque hallucinogènes d’apparence, sur nos photos de profils, dans notre Feed Instagram en encore même dans des expositions à New York. Il s’agissait des œuvres de Deep Dream, œuvres signés Google. Inspirées par le cerveau humain, ces images sont l’œuvre du Machine Learning. Ce domaine de l’intelligence artificielle a permis à Google de donner naissance à un courant artistique nommé « l’Inceptionnisme » (en référence au film Inception, 2010)
Les internautes se sont alors emparés de cet outil pour s’amuser à transformer leurs photos en « œuvres d’art ». Google a d’ailleurs organisé une exposition de peintureDeep Dream dont l’œuvre la plus chère s’est vendu pour 8 000 dollars.
En créant un courant artistique à part entière, l’AI impose ses compétences illimitées. L’art fut depuis toujours un moyen d’expression propre à l’humain qui semble nous glisser des mains.
Mais si le Machine Learning se base sur l’apprentissage, on peut alors parler ici de création et non d’œuvre ? Il est difficile d’imaginer un robot peindre une œuvre engagée telle que « La Liberté guidant le peuple » d’Eugène Delacroix.
Les capacités techniques de l’AI pour l’art
Ses dernières années, ces robots font craindre à certains un remplacement de l’Homme par la machine sur d’autres sujets. Car à défaut d’être capable de ressentir, l’AI est capable de simuler, d’imiter.
En avril 2016, des chercheurs néerlandais de l’université de Delft nous dévoilaient un nouveau Rembrandt. Poisson d’Avril certes, celui-ci ne fut pas peint par le si connu maître de la peinture mais par une intelligence artificielle. Aussi basé sur le système de Machine Learning, l’AI a appris le style et a analysé des centaines d’œuvres de Rembrandt Van Rijn. Reproduction
« Notre but était de créer une machine qui travaille comme Rembrandt afin de mieux comprendre ce qui fait d’un chef d’œuvre un chef d’œuvre« , a déclaré le directeur de projet Emmanuel Flores à la BBC. « Je ne pense pas que l’on puisse remplacer Rembrandt, il est unique ».
Exemple d’autant plus frappant : Taryn Southern, participante de l’émission American Idol en 2004, a créé son dernier album I Am AI à l’aide d’une étrange partenaire : Amper, l’AI de la musique moderne. L’artiste ayant de faibles notions de piano, Amper s’est chargé de toute la composition et production de l’album. Un travail qui se fait bon exemple de ce l’AI peut donner à la créativité humaine.
Selon Drew Silverstein, le PDG d’Amper Music, « la création humaine et les musiciens humains ne disparaîtront pas. Nous essayons juste de faire en sorte que passer plus de 10 000 heures et dépenser des milliers de dollars ne soit plus une nécessité pour partager et exprimer des idées. » En revanche, après écoute de « Break Free », extrait de l’album, il reste incontestable que Amper n’est pas encore équipé de détecteur de mauvais goût !
Voir la vidéo 3:03 à la source
L’AI a-t-il vraiment un sens du goût ?
Parlant de mauvais goût, Google Brain, Amper et ces autres intelligences artificielles serait ainsi capable d’agir comme des artistes mais sont-elles vraiment conscientes de la beauté de l’art ?
L’application mobile de photo EyeEm a récemment développé sa propre intelligence artificielle dans le but de sélectionner, de manière la plus objective possible, les meilleures photos sur la plateforme. EyeEm Vision AI analyse la lumière, les couleurs ainsi que la qualité de l’image selon des critères bien précis. Grâce à l’AI, le site a publié sa sélection des meilleures photos de l’année 2016. Voir une Image
EyeEm Vision AI est alors capable de comprendre une photo en temps réel et de déterminer sa qualité esthétique fondée sur des critères commerciaux.
Il ne s’agit pas ici d’une question de la machine remplaçant l’homme, mais plutôt d’une forme d’intelligence artificielle capable de critiquer l’art de manière peut-être plus objective.
Imitation, production et réalisation, créateur de courants artistiques, L’AI ne cesse de nous impressionner. Mais si ces machines sont capables de reproduire des créations ou de s’inspirer pour recréer, il existe tout de même une limite l’empêchant de rivaliser l’Homme au niveau émotionnel par exemple.
L’intelligence artificielle doit être perçue non comme une compétition face à l’Homme mais comme une opportunité, un complément à sa créativité.
ECV Digital - L’école du numérique et du web

Image associée
10.
Ai-Da, la première artiste humanoïde - Vidéo 3 minutes - Disponible du 12/06/2019 au 14/06/2022 - Découvrez l’offre VOD-DVD de la boutique ARTE
Un robot peut-il faire de l’art ? L’idée ne semble plus si aberrante depuis que l’entreprise de robotique anglaise Engineered Arts a mis au point un robot ultra-réaliste baptisé Ai-Da, la première à disposer de son propre corps. Ses caméras dans les yeux et sa main bionique lui permettent de reproduire ce qu’elle voit et de dessiner des portraits sans intervention humaine.
Journalistes : M. Bonnassieux, F. Zingaro - Pays : France Allemagne - Année : 2019
https://www.arte.tv/fr/videos/090645-000-A/ai-da-la-premiere-artiste-humanoide/
11.
Les réseaux antagonistes génératifs présentés par Wikipédia
En intelligence artificielle, les réseaux adverses génératifs (en anglais generative adversarial networks ou GANs) sont une classe d’algorithmes d’apprentissage non-supervisé. Ces algorithmes ont été introduits par Goodfellowet al.2014. Ils permettent de générer des images avec un fort degré de réalisme.
Un GAN est un modèle génératif où deux réseaux sont placés en compétition dans un scénario de théorie des jeux1. Le premier réseau est le générateur, il génère un échantillon (ex. une image), tandis que son adversaire, le discriminateur essaie de détecter si un échantillon est réel ou bien s’il est le résultat du générateur. L’apprentissage peut être modélisé comme un jeu à somme nulle1. L’apprentissage de ces réseaux est difficile en pratique, avec des problèmes importants de non convergence2.
Histoire
L’invention du concept courant et sa réalisation en un prototype eut lieu à Montréal, en 2014, lors d’une sortie au restaurant, par Ian Goodfellow3. Ses confrères doctorants célébraient leur diplôme et lui demandèrent assistance pour résoudre un problème de synthèse d’image4.
En art
Le collectif d’artistes français Obvious5 utilise les GANs comme outils de création artistique6. Les GANs génèrent une image fictive à partir d’une sélection d’images présentant des caractéristiques visuelles communes. Par la suite, l’image est améliorée, redéfinie pour être imprimée. La signature de leurs œuvres se caractérise par une formule mathématique indiquant la collaboration entre la technologie (associée à l’intelligence artificielle) et le processus artistique humain. Une de leur œuvre, intitulée Portrait d’Edmond de Belamy, possiblement en l’honneur de Ian Goodfellow (’Bon ami’ en français)7, a été vendue 432 500 $ en octobre 2018. Le directeur de l’Institut des Carrières Artistiques (ICART) en France, Nicolas Laugero Lasserre, commente : ’Leurs créations, sorte de collaboration entre l’humain et l’intelligence artificielle, marquent une césure et une prise de conscience dans l’histoire de l’art.’8
Au Japon, la société DataGrid utilise les réseaux antagonistes génératifs afin de générer des images de corps humains entiers9.
En Espagne, l’artiste et programmeur Mario Klingemann utilise lui aussi les GANs dans sa démarche de création artistique avec son projet My Artificial Muse.8,10
L’utilisation de ces algorithmes en art peut être associée à un courant nommé le « GANisme ».[réf. souhaitée]
Pour la recherche
En Russie, l’Institut de physique et de technologie de Moscou développe des GANs qui seraient capables d’« inventer » de nouvelles structures moléculaires dans le cadre de la recherche pharmaceutique. Ils seraient employés pour exploiter au mieux les propriétés spécifiques de molécules utilisées pour la fabrication de médicaments. L’existence de cette technologie pourrait apporter pour la recherche un gain de temps et de coûts, et améliorer l’efficacité ou réduire les effets secondaires de certains médicaments comme l’aspirine11. Sur le principe, les informations sur des composés aux propriétés médicinales reconnues sont intégrées dans le Generative Adversarial Autoencodeur, une extension du GAN, ajusté pour faire ressortir ces mêmes données12.
Artur Kadurin, programmeur pour le groupe Mail.Ru et conseiller indépendant chez Insilico Medecine, une entreprise américaine, annonce que : « Les GAN sont vraiment la ligne de front des neurosciences. Il est clair qu’ils peuvent être utilisés pour une gamme de tâches plus large que la génération d’images et de musique. Nous avons testé cette approche avec la bio-informatique et obtenu d’excellents résultats. »11
Cependant, bien que des progrès aient été notés dans l’apprentissage de ces GANs et qu’ils puissent apporter une meilleure compréhension en biologie et chimie, il n’en reste pas moins que leur utilisation dans des essais cliniques ne sont pas encore fiables13.
Article complet avec notes et références à voir sur ce site : https://fr.wikipedia.org/wiki/R%C3%A9seaux_antagonistes_g%C3%A9n%C3%A9ratifs
12.
La ‘Data Science’ devient créative avec les GAN – Document ‘wintics.com’ – Communiqué de ‘wintics.com’
Les champs d’application de la Data Science ne cessent de s’élargir. Les IA savaient déjà classer et prédire, elles deviennent créatives avec les GAN.
Les GAN, qu’est-ce que c’est ?
La technologie GAN (Generative Adversarial Networks), introduite en 2014 par Ian Goodfellow, est une approche innovante de programmation pour l’élaboration de modèles génératifs, c’est-à-dire capables de produire eux-mêmes des données.
Son développement rapide au cours des dernières années et ses multiples applications en font l’une des découvertes récentes les plus prometteuses du Machine Learning. Yann LeCun (patron de la recherche en IA chez Facebook) l’a d’ailleurs présentée comme « l’idée la plus intéressante des 10 dernières années dans le domaine du Machine Learning ».
En termes techniques, les GAN reposent sur l’entrainement non supervisé (unsupervised learning) de deux réseaux de neurones artificiels appelés Générateur et Discriminateur. Ces deux réseaux s’entrainent l’un l’autre dans le cadre d’une relation contradictoire :
- le Générateur est en charge de créer des designs (ex : des images)
- le Discriminateur reçoit des designs provenant (i) du générateur et (ii) d’une base de données constituée de designs réels. Il est en charge d’identifier la source de chaque design et ainsi de deviner si ces designs sont réels ou s’ils ont été générés par le Générateur.
A la suite du travail du Discriminateur, deux boucles de feedbacks transmettent aux deux réseaux de neurones l’identité des designs sur lesquels ils doivent s’améliorer.
- Le Générateur reçoit l’identité des designs sur lesquels il a été démasqué par le Discriminateur,
- Le Discriminateur reçoit l’identité des designs sur lesquels il a été trompé par le Générateur.
Les deux algorithmes entretiennent donc une relation gagnant-gagnant d’amélioration continue : le Générateur apprend à créer des designs de plus en plus réalistes et le Discriminateur apprend à identifier de mieux en mieux les designs réels de ceux provenant du Générateur.
Consulter le schéma - Prenons l’exemple bien connu des faussaires de billets de banque traqués par les policiers.
Le Générateur joue le rôle d’un faussaire qui produit une liasse de 100 faux billets de banque (dont les designs sont tous différents). Il la présente à un policier (le Discriminateur) qui, grâce à l’observation d’une base de données de billets authentiques qui lui a été transmise, a des connaissances basiques en identification de billets contrefaits. Le policier va donc analyser les billets du faussaire et les classer en deux catégories : ceux qu’il pense être vrais et ceux qu’il pense être faux. A chaque fois qu’un faux billet est identifié par le policier, celui-ci est renvoyé au faussaire. Cela va permettre à ce-dernier de connaitre les designs qui n’ont pas été capables de tromper la police et par symétrie, ceux qui ont été assez réalistes pour passer à travers les contrôles. Par cette logique d’apprentissage, le faussaire va pouvoir créer de nouveaux billets plus réalistes et les représenter au policier. Celui-ci donnera une nouvelle fois son verdict et ainsi de suite. Le processus s’arrête lorsque le faussaire (i.e. le Générateur) est capable de créer des billets qui trompent le policier (i.e. le Discriminateur) à tous les coups.
Quelques exemples d’application des GAN
Génération d’images
Jusqu’alors, les GAN ont surtout été utilisés pour la génération d’images avec des résultats satisfaisants : les images produites par des GAN peuvent être si réalistes que l’œil humain ne peut pas imaginer qu’elles ont été créées de toutes pièces (ou plutôt de tous pixels) par un ordinateur.
Voici quelques exemples d’images créées par des GAN.
Les images de chats présentées ci-dessous ne sont pas de vraies photos. Elles ont été générées par un modèle GAN entrainé sur la base de 10 000 photographies de chats. A noter que plus la base de données d’entrainement est grande, plus les images générées seront alors réalistes. Image de chats : Alexia Jolicoeur-Martineau/Meow Generator
Au-delà de cet exemple animalier, les applications business sont multiples pour les entreprises et peuvent concerner de nombreux secteur.
Génération de planches de designs pour l’automobile, le prêt-à-porter, l’ameublement, etc…
L’application la plus immédiate est des GAN est la génération d’idées de designs et de styles. Les GAN peuvent en effet produire des planches de styles qui pourraient alimenter la réflexion des responsables de la création et du design dans les entreprises, aussi bien dans la mode, que dans l’ameublement ou l’automobile.
Par exemple, les modèles de chaussures de sport présentés ci-dessous ont été générés par un modèle GAN. Image des chaussures : Deverall, Lee, Ayala/ Using Generative Adversarial Networks to Design Shoes
Génération de nouveaux personnages et de maps (i.e. décors) évolutives pour les jeux vidéo
Les jeux vidéo sont devenus de vrais blockbusters avec des budgets dignes des productions hollywoodiennes. Dans la course au réalisme et à l’immersion, les studios investissent des budgets significatifs pour créer des maps tentaculaires et des nouveaux décors qui permettent à chacun d’explorer le jeu de façon inédite.
Les GAN peuvent permettre aux éditeurs de générer des maps et des décors très réalistes en temps réel en fonction des déplacements dans le jeu des personnages. La « taille » des jeux devient alors infinie sans surcoût significatif de développement.
Génération de dessins techniques pour l’industrie
En alimentant un réseau GAN avec des dessins techniques et les caractéristiques correspondantes, les GAN sont capables de générer de nouveaux dessins techniques par exemple pour créer des châssis de voiture, des profils d’ailes d’avion, des coques de bateaux, etc.
C’est ce que présente Maurice Conti (responsable d’un grand laboratoire d’innovation : www.alpha.company) dans la vidéo ci-dessous où un algorithme génératif est utilisé pour créer un châssis de voiture de sport ultra-performant.
Prenons un autre exemple, celui du profil d’une aile d’avion, pour comprendre comment cela fonctionne. En alimentant un modèle GAN avec les données techniques d’un grand nombre de profils existants (matériaux, aérodynamisme, courbure, résistance, etc), le Générateur va apprendre à créer des dessins techniques répondant aux contraintes physiques et matériels de l’aviation, par exemple :
- tel type de matériau doit être utilisé sur telle partie de l’aile
- la structure doit être de telle épaisseur au niveau de l’embase des réacteurs.
Combinée à une fonction d’optimisation – par exemple, minimiser le coefficient de pénétration dans l’air – le modèle sera capable de générer des dessins (i) respectant les contraintes techniques et (ii) innovants en termes de performance.
Augmentation de la résolution d’images pour les enjeux de sécurité
Les images issues des vidéos de caméras de surveillance ne sont pas toujours d’une grande qualité et ne permettent pas nécessairement l’identification des éléments recherchés (ex : lecture d’une plaque d’immatriculation, reconnaissance d’un visage, visualisation d’un objet, etc).
Une sous-famille des GAN (les SRGAN : Super-Resolution Generative Adversarial Networks) a démontré sa capacité à augmenter la résolution d’images. Le Générateur produit alors des images de bonne qualité à partir d’images de qualité médiocre. Il les soumet au Discriminateur qui a été entrainé sur une base d’images de bonne résolution. Lorsque les images produites par le Générateur sont d’assez bonne qualité pour tromper le Discriminateur, le modèle s’arrête.
Les SRGAN peuvent ainsi être utilisés pour améliorer la qualité des images des caméras de vidéos surveillance et ainsi faciliter le travail d’identification des personnes qui les visionnent. Image : motiondsp.com
Et pourquoi pas l’écriture de textes (poésie, essais, romans, notes de synthèses, etc…)
On pourrait entraîner un réseau GAN sur la base de romans policiers et lui demander d’en générer un nouveau.
Le mot de la fin : créer et innover grâce aux GAN
Avec l’apparition des GAN, la Data Science s’est dotée d’un formidable outil de création et s’attaque ainsi à ce qui semblait être un des derniers prés carrés de l’intelligence humaine. Les premières applications se sont surtout développées autour de la génération d’images mais les possibilités de cette nouvelle technologie sont très nombreuses. Elle semble être un outil puissant au service de l’innovation produit.
Nous ne manquerons pas de publier sur ce blog les résultats des travaux de R&D de Wintics sur les GAN pour vous faire découvrir de nouvelles applications business.
Tech updates - Navigation d’article : Qu’est-ce qu’une smart city ?⟶
Une réflexion au sujet de « La Data Science devient créative avec les GAN » - Ping : GAN (Réseaux antagonistes génératifs)
Wintics Accueil - A propos : Carrières Blog – Contact : 55, rue La Boétie 75008 Paris - contact@wintics.com - Fièrement propulsé par WordPress | Thème : Sydney par aThemes.

Résultat de recherche d’images pour ’wintics’
Source : http://wintics.com/fr/quand-la-data-science-devient-creative-avec-les-gan/
Note : We highly recommend the interested readers to both read the initial paper “Adversarial Neural Nets”, that is really a model of clarity for a scientific paper, and watch the lecture video about GANs of Ali Ghodsi, who is truly an amazing lecturer/teacher. Additional explanation can be found in the tutorial about GANs written by Ian Goodfellow. Source : https://towardsdatascience.com/understanding-generative-adversarial-networks-gans-cd6e4651a29
13.
Image-to-Image Translation with Conditional Adversarial Nets - University of California, Berkeley In CVPR 2017 - Jun-Yan Zhu*, Taesung Park*, Phillip Isola, Alexei A. Efros. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv, 2017. [PDF][Webpage][Code - Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks / Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros (Submitted on 30 Mar 2017 (v1), last revised 15 Nov 2018 (this version, v6)) – Cornell University – Example results on several image-to-image translation problems. In each case we use the same architecture and objective, simply training on different data – Details / https://phillipi.github.io/pix2pix/ - Sources : https://arxiv.org/abs/1703.10593
Retour à la suite du texte introductif
14.
Enseignement des arts plastiques - Classe CHAAP - Qu’est-ce que c’est ? Publié le 02.06.2019 – Document officiel Arts plastiques – Éduscol France
Des classes à horaires aménagés en arts plastiques (CHAAP) peuvent être organisées dans les écoles élémentaires et les collèges pour permettre aux élèves de recevoir, dans le cadre des horaires et programmes scolaires, un enseignement artistique renforcé. Les autres domaines artistiques visés sont la musique, la danse, et, depuis 2009, le théâtre.
Ces dispositifs spécifiques sont construits en partenariat avec des institutions culturelles. Ils prennent appui sur une équipe motivée et volontaire constituée autour d’un projet pédagogique global. Ils sont intégrés au projet d’école ou au projet d’établissement.
L’ouverture d’une classe à horaire aménagé s’effectue dans le cadre de la carte scolaire. Elle s’inscrit dans les schémas départementaux pour les enseignements artistiques mis en place avec les collectivités territoriales.
La formation dispensée dans ces classes fait l’objet d’une évaluation régulière qui s’exerce au sein de l’école ou du collège et au niveau académique. La concertation entre l’ensemble des partenaires intervenant dans la formation concourt à la mise en place d’une observation continue de l’élève.
Quelques exemples de CHAAP en France
- Collège La Châtaigneraie - Autun (académie de Dijon)
- Collège Font-Belle - Ségonzac (académie de Poitiers)
- Collège Alienor d’Aquitaine - Bordeaux (académie de Bordeaux)
- Collège Robert Doisneau - Clichy-sous-Bois- (académie de Créteil)
- Collège Léo Lagrange - Le Havre - (académie de Rouen)
Ministère de l’Éducation nationale et de la Jeunesse - Direction générale
de l’enseignement scolaire / Direction du numérique pour l’éducation - Certains droits réservés.

https://eduscol.education.fr/typo3temp/pics/f5a2878313.png
15.
Enseignement Art & IA : résidence artistique en recherche/création et intelligence artificielle au Québec Canada Opération 2019
Appel de candidatures - < Retour aux concours et appels de projets Appel de propositionsFinalistesLauréat
Art & IA : Résidence artistique en recherche / création et intelligence artificielle- Illustration
L’Office national du film du Canada (ONF), le Partenariat du Quartier des spectacles (PQDS), Element AI, Google et le Conseil des arts de Montréal (CAM) s’associent pour offrir à un artiste professionnel ou à un collectif artistique multidisciplinaire de Montréal une résidence de recherche et création d’une durée de six mois.
D’une durée de six mois, d’avril à octobre 2019, et assortie d’un budget de 50 000 $ et de 200 heures d’accompagnement d’experts en IA, cette résidence permettra à l’artiste ou au collectif artistique choisi de collaborer directement avec des chercheurs et des développeurs en IA et d’accéder aux plus récents développements de cette discipline. Le ou les artistes sélectionnés pourront ainsi créer le prototype d’une œuvre, d’une expérience ou d’une installation artistique pouvant se déployer en exploitant de façon originale les potentialités de l’IA. De leur côté, les chercheurs et les développeurs bénéficieront d’une approche créative différente de celles auxquelles ils sont habitués.
En plus de favoriser des échanges autour des possibilités et des enjeux amenés par l’IA, cette résidence sera aussi l’occasion d’aborder plus précisément le rôle potentiel de l’IA dans le développement des villes de demain et dans la participation citoyenne, au cœur de Montréal.
Critères de sélection
Les propositions seront évaluées par un comité composé d’un représentant de chacune des organisations partenaires (ONF, PQDS, Element AI, Google et CAM) et d’autres représentants du milieu artistique selon les critères suivants :
• Pertinence du projet quant à l’utilisation de l’IA ;
• Qualité de la démarche artistique et des projets antérieurs ;
• Intérêt de la réflexion amenée sur la ville de demain et sur la participation citoyenne ;
• Potentiel de « contamination positive » entre les milieux de l’art et de l’IA ;
• Faisabilité du projet.
Pour connaître tous les détails de l’appel > consultez : Art & IA, résidence artistique en recherche/création et intelligence artificielle
Dépôt d’une proposition - Date limite : Dépôt des propositions | au plus tard le 5 Février 2019, à midi - Le dossier doit inclure :
• une description du projet en lien avec les critères de sélection (intention, démarche, lien avec l’IA) ;
• une évaluation sommaire des besoins d’accompagnement et d’équipements ;
• le budget et l’échéancier sommaires ;
• le nom de l’artiste ou les noms des membres du collectif ; CV condensé de l’artiste ou celui de chacun des membres du collectif, y compris la présentation de projets antérieurs ou des liens vers ces projets.
La section description du projet doit compter cinq pages maximum écrites au recto seulement (les pages supplémentaires ne seront pas lues). Le dossier doit être fourni en un seul exemplaire de format 21,6 cm X 27,9 cm (8 ½ po X 11 po) et être transmis par courriel seulement. Seuls les documents exigés seront transmis aux membres du comité d’évaluation.
Si votre dossier est volumineux, veuillez le faire parvenir par WeTransfer.
Objectifs
La résidence a été développée en fonction des objectifs suivants :
• Soutenir et stimuler la collaboration entre deux communautés phares de Montréal (IA et milieu artistique) ;
• Donner l’occasion aux artistes d’accéder aux plus récents développements de l’IA ;
• Offrir aux artistes des conditions leur permettant de faire de la recherche et création afin de développer un prototype incorporant l’IA ;
• Offrir aux chercheurs et aux développeurs en IA un regard créatif sur leurs travaux tout en ayant la possibilité de développer des outils d’IA en collaboration avec des artistes ;
• Favoriser les échanges sur les impacts et les possibilités qu’apporte l’IA dans la sphère artistique ;
• Créer le prototype d’une oeuvre, d’une expérience ou d’une installation artistique pouvant se déployer dans l’espace public en exploitant de façon originale les potentialités de l’IA ;
• Susciter une réflexion sur le rôle que peut jouer l’IA dans le développement des villes de demain et dans la participation citoyenne.
Durée de la résidence et montant du budget +
Le jury - Un jury composé de sept personnes sélectionnera les six finalistes et le lauréat :
- Pascale Daigle, directrice de la programmation, Partenariat du Quartier des spectacles
- Hugues Sweeney, Producteur exécutif du studio intéractif, ONF
- Marie-Michèle Cron, Conseillère culturelle - arts numériques et arts visuels, Conseil des arts de Montréal
- Valérie Becaert, Directrice groupe de recherche, Element AI
- Jean-François Belisle, Directeur général et conservateur en chef, Musée d’art de Joliette
- Kakim Gho, Artiste visuel et commissaire
- Nicolas Brault, M.A., Cinéaste - Professeur assistant, Baccalauréat en Art et science de l’animation, École de design. Université Laval
Porte-parole : Sandra Rodriguez et David Usher
Lisez l’entrevue avec les deux porte-parole afin d’en savoir plus à propos de cette résidence et à qui cet appel s’adresse.
Sandra Rodriguez Photo - « Si la tâche des scientifiques est d’interroger, celle des artistes est de déranger. Les développements en IA regroupent un ensemble de technologies, et je trouve important que les artistes, les citoyens ne soient pas laissés en marge de décisions qui influencent déjà nos sociétés. Avec ce maillage, on vient offrir une place aux créateurs afin qu’ils contribuent à secouer nos imaginaires, pour mieux penser ensemble nos villes de demain. » — Sandra Rodriguez, directrice de création, réalisatrice et sociologue reconnue des nouveaux médias. Biographie +
David Usher Photo - « L’IA est un outil technologique à la fine pointe, mais qui demeure peu accessible aux créateurs, autant par sa rareté que par son coût. Cette résidence permet non seulement que les artistes se saisissent de cet outil, mais qu’ils soient appuyés et accompagnés, pour concrétiser leurs idées, par des spécialistes de la création et des nouveaux récits comme l’ONF, le Partenariat du Quartier des spectacles et le Conseil des arts de Montréal, ainsi que par des experts qui repoussent les limites des nouvelles technologies comme Element AI et Google AI. Cela permet à l’IA d’explorer de nouveaux territoires et d’élargir sa palette de possibilités. » — David Usher, artiste, auteur à succès, entrepreneur et conférencier de premier plan - Biographie +
Une union d’expertises unique : la résidence réunit les expertises de haut niveau de partenaires, chacun dans leur domaine, et les associe à la force de création des artistes multidisciplinaires.
Autre ressource :
Conseil québécois des arts médiatiques (CQAM) - Guide de l’industrie ... www.lienmultimedia.com ›
16.
Intelligence artificielle au Québec Canada : les artistes sont-ils prêts ? Publié le mardi 22 janvier 2019
Sandra Rodriguez, Mathieu Marcotte et Hugues Sweeney - Photos : Radio-Canada / Olivier Lalande
L’Office national du film (ONF), le Quartier des spectacles de Montréal, l’entreprise Element AI, Google et le Conseil des arts de Montréal offrent à un artiste ou à un collectif de Montréal une résidence artistique en recherche et en création en lien avec l’intelligence artificielle. Cette résidence est dotée d’un budget de 50 000 $ et comprend 200 heures d’accompagnement d’experts en intelligence artificielle. Catherine Perrin en discute avec Sandra Rodriguez, coporte-parole de l’initiative, Hugues Sweeney, de l’ONF, et Mathieu Marcotte, d’Element AI.
En complément : Art et IA : résidence artistique en recherche/création et intelligence artificiellesur le web - Radio-Canada n’est aucunement responsable du contenu des sites externes - Suivre ICI Radio-Canada Première Conditions d’utilisation Ombudsman Contactez-nous
Tous droits réservés © Société Radio-Canada 2019 – Source : https://ici.radio-canada.ca/premiere/emissions/medium-large/segments/panel/102967/intelligence-artificielle-artistes-prets-rodriguez-sweeney-marcotte
17.
Coder le monde : intelligence artificielle et création artistique en France – Annonce de rencontres 14/06/2018 - Lieu : Centre Pompidou, Place Georges Pompidou - Paris
Le Forum Vertigo organise un cycle annuel de rencontres internationales entre scientifiques et artistes, ingénieurs et intellectuels. Vertigo : zoom avant sur le présent vertigineux. L’édition 2018 du Forum dresse un état de l’art des usages du code et de l’algorithmique dans différents champs de la création – arts visuels, musique, danse, littérature, architecture. Il interroge les nouveaux modes de constitution du savoir opérés par l’impact puissant des humanités numériques qui hybrident science informatique et sciences humaines et sociales à partir de corpus documentaires numérisés.
Cette réflexion est particulièrement aiguë et actuelle avec la généralisation des technologies d’intelligence artificielle , ouvrant de nouveaux procédés de génération automatique à partir de l’apprentissage massif de collections de contenus. Pour la création comme pour les processus d’apprentissage, l’utilisation des Big Data pose frontalement la question de l’auteur, de son autorité, de sa liberté et de son unicité, donc aussi de son existence.
Bertrand Braunschweig, directeur du centre de Saclay, animera une table ronde jeudi 14 juin de 16h à 18h sur l’intelligence artificielle dans la création musicale.
En lien avec l’exposition ’Coder le monde’ et ’Ryoji Ikeda’ au Centre Pompidou, dans le cadre de Mutations/Créations 2*.
Programme 2018 détaillé :
Mercredi 13 juin dès 14h30 Humanités numériques : coder-décoder la connaissance
Mercredi 13 juin à 19h00 Débat / Code et intelligence artificielle : de nouveaux maîtres pour la connaissance et la création ?
Jeudi 14 juin dès 11h00 Coder le monde.1
11h | Algorithmique, art et société - Avec Vera Bühlmann , auteur, philosophe et professeur au département d’architecture de l’ETH Zürich
Pierre Cassou Noguès , philosophe, université Paris 8
L’objet de cette session introductive à la thématique Coder le monde est de dresser une perspective épistémologique et historique des rapports, à la fois fondamentaux et contingents à l’évolution des techniques, liant code et art, raison et imaginaire, signe et sens, humain et machine.
14h30 | Coder le corps - Animation : Sarah Fdili Alaoui , artiste et maitre-assistant de conférences, université Paris Saclay
Avec Rocio Berenguer , artiste, et directrice artistique de Pulso
Scott deLahunta , codirecteur de Motion Bank , chercheur à la Coventry University (C-DaRE) et à la Deakin University
Marc Downie , artiste numérique, OpenEndedGroup
Pierre Godard , artiste et directeur artistique de Le principe d’incertitude
Christian Mio Loclair , artiste et chorégraphe, Creative Director à Waltz binaire
Chris Salter , artiste et professeur à l’université Concordia de Montréal
Liz Santoro , danseuse et directeur artistique de Le principe d’incertitude
Associant artistes et chercheurs à l’interface entre danse et technologies numériques, cette table ronde questionne les fondements de la technologie dans la création chorégraphique. Comment cette hybridation affecte-t-elle les processus de création et les méthodes de recherche en informatique ? Quel langage commun émerge-t-il de ces collaborations ? Quels sont les défis technologiques liés à la complexité du mouvement dansé et sa qualité vécue et expérientielle ?
16h | Intelligence artificielle et générativité
Animation : Bertrand Braunschweig , directeur du centre Inria de Saclay Île de France
Avec Philippe Esling , maitre de conférences, Sorbonne Université, Ircam-STMS
Claire Giraudin , directrice de Sacem Université
Daniele Ghisi , compositeur et mathématicien
François Pachet , directeur du Creator Technology Research Lab, Spotify
Opérant par apprentissage de corpus de données massives – sons, images, textes – les algorithmes actuels d’intelligence artificielle sont porteurs d’une puissance inédite pour la production d’artefacts d’une vraisemblance d’autant plus troublante que leur fonctionnement est mal compris. Quelles sont leurs limites et mettent-ils en péril le statut de l’auteur en tant que tel ? Leur maîtrise est-elle porteuse de nouvelles heuristiques pour la création artistique ?
Vendredi 15 juin dès 12h00 Journée Starts Residencies
Samedi 16 juin dès 11h00 Coder le monde.2
*Coproduction Ircam/La Parole/BPI–Centre Pompidou, Bibliothèque nationale de France. Avec le soutien de la DG Connect de la Commission européenne dans le cadre de l’initiative STARTS (Science Technology and the ARTS) . En partenariat avec Sacem Université, FUTUR.E.S in Paris, Usbek & Rica et France Culture.
Mots-clés : Intelligence artificielle Inria Saclay - Île-de-France Arts Bertrand Braunschweig
Lire aussi :
Intelligence artificielleEntretien avec Bertrand Braunschweighttps://www.inria.fr/actualite/actu...
Intelligence artificielleInria au coeur du débat nationalhttps://www.inria.fr/centre/saclay/...
Intelligence artificielleBertrand Braunschweig sur France Inter nous parle d’intelligence artificiellehttps://www.inria.fr/centre/saclay/...
Livre blanc sur l’intelligence artificielle Livre BlancIntelligence Artificielle, les défis actuels et l’action d’Inriahttps://www.inria.fr/actualite/actu...
Siège et centres de recherche Inria : SiègeBordeaux - Sud-OuestGrenoble - Rhône-AlpesLille - Nord EuropeNancy - Grand EstParisRennes - Bretagne AtlantiqueSaclay - Île-de-FranceSophia Antipolis - MéditerranéeInria Chile
Accès direct : Europe Equipes de recherche Marchés publics Fournisseurs et prestataires Information et édition scientifiques Rapports d’activité - RAweb Archive ouverte - HAL-Inria Une question de science à poser ?
Ressources : Logo InriaEspace pressePhotothèqueVidéothèqueInria sur Canal-U
Plan du site Nous contacter Marchés publics Crédits Données personnelles Mentions légales
Le Programme de Résidence en Recherche Artistique de l’IRCAM offre aux artistes de toutes disciplines, la possibilité de collaborer avec une ou plusieurs équipes de recherche de l’Ircam, dans le cadre d’une résidence pouvant se prolonger dans un centre de création partenaire. Pour la 11ème édition de son Programme de Résidences en Recherche Artistique, l’Ircam s’allie au Zentrum für Kunst und Medien (ZKM), Karlsruhe, Allemagne et à la Société des Arts Technologiques (SAT), Montreal, Canada. Les bienfaits de la résidence sont nombreux : Offrir un temps de réflexion sur sa pratique ; Travailler au contact des chercheurs pour approfondir ensemble une piste de recherche artistique ; Elaborer ou perfectionner un outil de création innovant ; Mener une recherche artistique expérimentale ; Produire le prototype d’un artefact ; Composer l’esquisse d’une pièce, d’une performance ; Tester une configuration, un dispositif audio/vidéo immersif 360 degrés tel que la Satosphère de la SAT ou le Klangdom du ZKM. Un panel international d’experts, comprenant les responsables des équipes-projets d’accueil concernés, évalueront chacun des dossiers. L’évaluation est basée sur l’originalité du projet et son caractère innovant, les aspects collaboratifs, l’expérience et la capacité à entreprendre le projet proposé.
Consulter les éditions précédentes : http://www.ircam.fr/creation/residence-en-recherche-artistique/
Appel à propositions
Pour la 11ème édition de son Programme de Résidence en Recherche Artistique, l’Ircam invite les artistes de toutes disciplines, à soumettre un projet original de recherche artistique, s’inscrivant dans la collaboration avec une ou plusieurs équipes de recherche de l’ Ircam. Cette année un track spécial est dédié à l’orchestration et intelligence artificielle.
- Acoustic and Cognitive Spaces
- Perception and Sound Design
- Sound Analysis-Synthesis
- Sound Systems and Signals : Audio/Acoustics, InstruMents
- Musical Representations
- Analysis of Musical Practices
- Sound Music Movement Interaction
- Special track : Artificial Intelligence and Orchestration
La résidence peut se prolonger dans un des lieux de co-résidence partenaire :
- la Société des Arts Technologiques - SAT, Montreal, Canada
- Zentrum für Kunst und Medien – ZKM, Karlsruhe, Allemagne
Les candidats sont invités à rentrer en contact avec les équipes et les lieux de co-résidence pour élaborer au mieux leurs propositions.
Les bienfaits de la résidence sont nombreux : Offrir un temps de réflexion sur sa pratique ; Travailler au contact des chercheurs pour approfondir ensemble une piste de recherche artistique ; Elaborer ou perfectionner un outil de création innovant ; Mener une recherche artistique expérimentale ; Produire le prototype d’un artefact ; Composer l’esquisse d’une pièce, d’une performance ; Tester une configuration, un dispositif…
Les candidatures se font uniquement en ligne sur la plateforme Ulysses. Après la création d’un compte sur la plateforme, les candidats peuvent soumettre leur proposition. La date limite de soumission est fixée au 21 Novembre 25 Novembre 2018 (minuit heure de Paris).
Un panel international d’experts, comprenant les responsables des équipes-projets d’accueil concernés, évalueront chacun des dossiers. Il est conseillé de prendre contact avec ces équipes-projets d’accueil en amont de la candidature, afin d’affiner la proposition. L’évaluation est basée sur l’originalité du projet et son caractère innovant, les aspects collaboratifs, l’expérience et la capacité à entreprendre le projet proposé. Dans des cas particuliers, un comité spécial organisé par l’Ircam et les partenaires interviewera certains candidats.
En ce qui concerne les résidences conjointes IRCAM/ZKM et IRCAM/SAT, Les propositions doivent mettre en avant les aspects complémentaires et collaboratifs d’une co-résidence au sein des deux institutions.
A l’issue de la sélection finale par un jury international, les lauréats de l’appel à résidence 2019 du Programme de Résidences en Recherche Artistique seront annoncés, lors des ateliers du forum, à Paris, le 27 Mars 2019.
Chaque lauréat se verra accorder une résidence à l’Ircam, au sein de l’équipe-projet d’accueil sollicitée, éventuellement suivie par une période de co-résidence au ZKM ou à la SAT, pendant une période totale déterminée (comprise entre 2 semaines et six mois), s’étalant de septembre 2019 à décembre 2020. Chaque lauréat recevra l’équivalent de 1200 euros par mois pour couvrir ses frais.
Pour en savoir plus sur l’Ircam : http://www.ircam.fr
_Pour en savoir plus sur le ZKM : http://zkm.de/
_Pour en savoir plus sur la SAT : http://sat.qc.ca/
Instructions pour la soumission
Créer un compte (ou utiliser un compte déjà existant) sur http://www.ulysses-network.eu/. Après avoir complété votre profil, cliquez sur « apply » sur la page du concours :
http://www.ulysses-network.eu/web/competitions/researchresidency-2019/
Puis démarrer votre soumission. Vous pouvez enregistrer votre application comme brouillon avant la date limite de soumission. La plateforme vous avertira de toute incomplétude avant la soumission finale.
Matériel requis
- Le formulaire de candidature inclue des informations susceptibles d’être publiées et d’autres, destinées à la seule évaluation du dossier (respectivement public et private). Certaines informations sont obligatoires et d’autres facultatives.
- Une catégorie « information personnelle »
- Nom, prénom, âge, nationalité, date de naissance, adresse
- Avez vous besoin d’un logement à Paris ?
- Une courte biographie et une description de votre champ d’activité
- Un CV, une lettre de motivation, une description de précédents travaux et si possible, une lettre de recommandation
- Votre expérience dans la collaboration avec des équipes de recherche de l’IRCAM ou autre.
- Une catégorie « Présentation du projet »
- Titre, résumé, et proposition détaillée.
- Plan de travail, budget prévisionnel et planning de la résidence.
- Objectif visé et besoins spécifiques.
- Aspects collaboratifs
- Une équipe-projet d’accueil principale, et d’autres, secondairement associées
- La qualité de présentation, la précision des informations et l’élaboration des propositions sont évaluées par le jury. Il est conseillé d’étayer votre plan de travail par un état de l’art justifiant le caractère innovant de votre approche.
- Le planning prévisionnel des résidences doit répartir la durée effective de la résidence (2 semaines à 6 mois) sur la période allant de Septembre 2019 à Décembre 2020.
- Le plan de travail, le budget prévisionnel, le planning de la résidence ainsi que les objectifs visés n’ont aucun caractère contractuel et son purement informatif. Après la sélection, ces éléments seront adaptés et mis en cohérence avec les activités de l’équipe-projet d’accueil.
Règles
- La candidature doit être réalisée par une personne physique et non par un collectif. Si le projet est co-écrit à plusieurs, la candidature devra être portée par un seul candidat référent de la proposition.
- Les dossiers de candidature peuvent être en français ou en anglais (pour les co-résidences IRCAM/ZKM, les dossiers doivent être en anglais).
- La procédure de participation est strictement en ligne. Aucun matériel envoyé par mail ne sera considéré.
- Date limite de soumission : 21 Novembre 25 Novembre 2018 (minuit heure de Paris). Aucune dérogation ne sera accordée.
- Toute demande incomplète selon les directives ci-dessus mentionnées sera rejetée. Les auteurs sont responsables du contenu du dossier de candidature et de sa vérification.
- Tous les documents privés soumis sont considérés comme confidentiels et ne seront pas utilisés par l’Ircam ou une tierce partie sans le consentement du demandeur. Les informations publiques pourront être utilisées par l’Ircam à des fins de communication.
- L’Ircam se réserve le droit de mettre un terme à la résidence suite à sa sélection, à toute étape de son déroulement et de refuser la présentation d’un projet jugé incomplet, insuffisant, éthiquement non conforme à ses politiques. Dans un tel cas, l’Ircam pourra le retirer entièrement de son programme de résidence, et ce, à tout moment et sans préavis.
- Dans le cas des co-résidences IRCAM/ZKM et IRCAM/SAT, chaque institution contractera indépendamment avec les résidents, dans le cadre de la législation locale en vigueur.
- Le Programme de Résidence en Recherche Artistique ne défraie pas les frais de déplacement ni de Per diem pour les artistes sélectionnés et leurs collaborateurs. Les frais occasionnés par la résidence doivent être détaillés dans le budget prévisionnel, spécifiant ce que l’artiste, le programme et/ou une tierce partie (producteur ou autre source de co-financement) prévoit d’investir dans le projet.
- Le Programme de Résidence en Recherche Artistique peut rédiger une lettre d’intention pour faciliter la recherche de financement ou de subventions ;
- L’Ircam offre le soutien de son département Interfaces Recherche/Création pour la diffusion, l’archivage audiovisuel et les communications reliées au projet dans ses réseaux et sur son site web ;
- Le Programme de Résidence en Recherche Artistique n’est ni une commission pour une œuvre d’art ni une résidence scientifique.
Appel à Résidence en Recherche Artistique 2018-2019→
About IRCAM Forum Shop Contact & Support
About Bienvenue À propos du Forum Ircam Comment rejoindre le Forum Ircam ? Offres d’abonnement Autorisation des logiciels Documentations Logiciels FAQ – foire aux questions
Shop Devenir membre My IRCAM Forum Subscriptions Partner’s Products Event’s Tickets
Legal Conditions générales de vente Contrat de licence Forum Ircam
Contact Website administration Commercial board Technical board General Discussion Room Privacy Policy
©IRCAM, 2019. All rights reserved. v0.1.12 - Source : https://forum.ircam.fr/article/programme-de-residence-en-recherche-artistique-2019-2020/
19.
Existe-t-il des IA créatives ? IA Lab - P. Lemberger -16 mars 2018 – Document ‘weave.eu’ - Profil linkedin de Pirmin Lemberger - Photo Profil linkedin de Pirmin Lemberger
Résumé
Certains modèles de machine learning sont aujourd’hui capables de générer des images fictives d’un réalisme surprenant. Cet article est le premier d’une série de deux consacrés à ces modèles dit génératifs. Il décrit comment fonctionnent les deux principaux modèles utilisés pour créer ou modifier des images : les Variational Auto-Encoders (VAE) et les Generative Adversarial Networks (GAN). Plus largement, il aborde aussi la question de savoir en quoi consiste au juste leur « créativité ». Le second article sera consacré aux enjeux UX de ces modèles lorsqu’ils sont utilisés dans un contexte d’intelligence augmentée.
- IA – après l’apprentissage, la création ?
- Qu’est-ce qu’un modèle génératif ?
- Pas encore de e-Picasso, mais…
1. IA – après l’apprentissage, la création ?
Si l’IA désigne globalement les techniques qui visent à automatiser, un jour, l’ensemble des processus cognitifs humains, il faut bien se rendre à l’évidence que l’immense majorité des applications ne reposent aujourd’hui que sur quelques formes rudimentaires d’apprentissage. L’apprentissage supervisé, qui présuppose la disponibilité d’exemples de référence pour lesquels on connaît la réponse souhaitée, et l’apprentissage par renforcement, qui consiste à optimiser une stratégie par interaction avec un environnement en vue de maximiser une récompense, en sont les deux formes les plus courantes.

https://weave.eu/app/uploads/2018/03/exemples.png
Figure 1 : (a) un Deep Dream (b) un Rembrandt synthétique (c) application d’un style Van Gogh à une photo quelconque.
Plus récemment, on a vu apparaître des applications du Deep Learning dans le domaine de la création artistique grâce aux modèles génératifs qui implémentent comme nous le verrons une forme simple d’apprentissage non-supervisé. Ainsi sait-on aujourd’hui visualiser avec Deep Dream les rêves (ou les cauchemars peut-être) d’un réseau de neurones, recréer un Rembrandt plus vrai que nature ou encore appliquer un style Van Gogh à n’importe quelle photo, comme l’illustre la figure 1. Le domaine « littéraire » n’est pas en reste puisque des réseaux de neurones récurrents sont désormais capables de rédiger des pastiches à la manière de Shakespeare.
Enfin, sans parvenir pour l’instant à égaler Miles Davis, les réseaux de neurones se sont également essayés à l’improvisation jazz.
Bien que les réseaux génératifs profonds en soient à leurs premiers balbutiements, on pourrait dès à présent y consacrer un ouvrage entier. Notre objectif ici est simplement de répondre à la question figurant dans le titre de cet article. Sans spéculations grandiloquentes, sans envolées lyriques, mais de manière argumentée, en nous appuyant sur une compréhension approfondie des mécanismes à l’œuvre dans les deux principaux modèles génératifs utilisés pour créer des images synthétiques réalistes.
2. Qu’est-ce qu’un modèle génératif ?
Les modèles génératifs sont des modèles de machine learning capables de synthétiser des objets complexes, comme des textes, des images ou de sons, « similaires » à ceux d’une liste d’exemples. En termes un peu plus techniques, on peut dire que les modèles génératifs sont capables d’apprendre une distribution de probabilité sur des objets complexes, distribution que l’on pourra ensuite échantillonner pour produire des exemplaires inédits mais ressemblants aux exemples.
Les applications de ces modèles génératifs sont multiples :
- La création, interactive ou non, d’images ou de vidéos dans un contexte artistique ou marketing [DMG]. C’est le sujet principal de cet article.
- La simulation d’évolutions vraisemblables d’environnements physiques en vue de planifier de tâches en robotique ou dans un contexte d’apprentissage par renforcement [IGF].
- La mise à l’épreuve de notre aptitude à comprendre la structure d’objets complexes du monde réel en essayant d’en générer des exemplaires crédibles.
- La génération d’images en haute résolution réalistes à partir d’image en basse résolution.
- L’enrichissement d’un jeu de données dans un contexte d’apprentissage semi-supervisé où l’on dispose de peu de données étiquetées.
Notre définition intuitive d’un modèle génératif manque hélas de rigueur puisque nous n’avons pas pris la peine de préciser le sens de l’adjectif « similaire ». Si on la prenait au pied de la lettre on pourrait construire par exemple un algorithme qui se contenterait de régurgiter dans le désordre les images fournies en entrée et arguer, avec un zeste de mauvaise foi, que les images ainsi produites sont bien similaires aux exemples ! On conçoit par conséquent que, pour être utile, un algorithme génératif se doit d’incorporer une notion de régularité qui lui permettra d’interpoler entre les exemples qu’il a vu pour en générer de nouveaux qui ne soient pas strictement identiques. La définition mathématique rigoureuse de cette notion de similarité reste à ce jour un problème ouvert pour les objets complexes du monde physique [MAL]. Par chance, les techniques de Deep Learning sont aujourd’hui en avance sur les développements théoriques. De fait, on sait construire des modèles génératifs qui font l’affaire en pratique, même si nous comprenons encore mal la nature de la régularité qu’ils exploitent implicitement.
Dès à présent nous limiterons notre discussion à la génération d’images.
Les auto-encodeurs (AE)
Les auto-encodeurs sont des modèles d’apprentissage non supervisé qui vont nous permettre de comprendre dans un premier temps une notion importante dans le cadre des modèles génératifs : la notion de variables latentes.
Considérons par exemple une collection d’images de visages humains d’une résolution de 1000 x 1000 pixels et posons-nous la question de savoir combien de paramètres sont nécessaires au minimum pour décrire correctement un visage en particulier. L’âge, le sexe, la coupe de cheveux, le teint, l’aspect souriant ou non, … sont probablement indispensables mais, de tout évidence, insuffisants. Peut-être quelques dizaines de paramètres suffiront-ils si à condition d’accepter qu’ils n’aient pas tous une interprétation directe évidente. On appelle ces paramètres des variables latentes. La figure 2 illustre la situation : parmi toutes les images carrées d’un million de pixels, seule une infime fraction correspondent effectivement à des visages humains.
Figure 2 : L’espace des images est de dimension 1000’000 (trois dans la figure). Les images de visages constituent une infime partie de cet espace qui correspond à une surface de dimension beaucoup plus faible, peut-être 50 (deux dans la figure). Les coordonnées sur cette surface de faible dimension sont les variables latentes.
Les 50 variables latentes (λ1, λ2, …, λ50) peuvent être envisagées comme une forme compressée de l’information visuelle. A, chaque point dans l’espace des variables latentes correspond un visage, si bien que parcourir cet espace latent revient à parcourir l’ensemble des visages humains. Les auto-encodeurs sont des systèmes d’apprentissage non supervisé qui permettent :
- De construire un espace de variables latentes. Les différentes variables latentes que l’algorithme découvre n’ont cependant pas vocation à être directement interprétables, contrairement à celles de la figure 2.
- De reconstruire une image à partir d’un point dans l’espace latent.
Leur principe de fonctionnement est illustré dans la figure 3, il utilise un réseau de neurones.
Figure 3 : L’architecture d’un auto-encodeur constitué d’un encodeur et d’un décodeur symétriques. Seules les connexions entre les 3 premières couches sont représentées, les autres étant symétriques.
Un AE est un réseau de neurones constitué de plusieurs couches connectées de manière symétrique comme l’illustre la figure 3
[1]. Les couches d’entrée et de sortie sont identiques et sont celles qui possèdent le plus grand nombre de neurones, pour une image en noir et blanc chaque pixel correspond à un neurone. Le nombre de neurones de la couche centrale correspondant au nombre de variables latentes que l’on souhaite découvrir. Plus les nombres de couches et de neurones sont importants, plus l’auto-encodeur sera capable d’apprendre à encoder des images complexes. Ces nombres sont des hyperparamètres qu’il faudra ajuster par tâtonnements pour parvenir à une reconstruction optimale sans trop de ressources.
Durant l’entraînement de l’AE on lui présente une liste d’images en entrée et on lui demande d’apprendre à les reconstruire aussi précisément que possible sur la couche de sortie en minimisant une erreur de reconstruction qui évalue la différence entre l’image originale et l’image reconstruite
[2]. Les couches comprises entre l’entrée et la couche de variables latentes sont alors à envisager comme un encodeur et les couches entre les variables latentes et la sortie comme un décodeur. En d’autres termes, on demande à l’encodeur de compresser l’information pour la faire tenir dans un petit nombre de variables latentes et au décodeur de reconstruire cette information du mieux qu’il peut. Sur les données qu’on lui fournit l’AE ne fait donc globalement… rien ! Cette opération en apparence triviale ne l’est pas en réalité car le faible nombre de neurones de la couche centrale constitue un goulet d’étranglement qui force l’AE à trouver une représentation parcimonieuse des données qu’on lui a présenté
[3]. Il faut bien réaliser que ce mécanisme de compression ne fonctionnera correctement que pour des données de même nature que celles avec lesquelles on a entrainé l’AE. Si on présente une image de camion plutôt qu’un visage à l’AE, l’encodage n’aura aucun sens et la reconstruction sera impossible car l’AE cherchera désespérément à interpréter un camion comme un visage !
Utiliser un AE en mode génératif revient alors à échantillonner des vecteurs de variables latentes (λ1, λ2, …, λ50) puis à reconstruire les images associées au moyen du décodeur. Ce processus est créatif, si l’on veut, dans la mesure où les visages générés de cette manière seront différents de ceux du jeu d’entraînement. Il n’y a aucune raison en effet pour que les vecteurs latents choisis au hasard coïncident avec à ceux des images du jeu d’entraînement.
Les auto-encodeurs variationnels (VAE)
Hélas les auto-encodeurs simples similaires à celui qui est représenté sur la figure 3 fonctionnent mal en pratique. Ils ne permettent pas de réaliser pleinement l’idée illustrée sur la figure 2, à savoir un encodage continu de représentations qui permettrait de se déplacer sur l’espace des visages pour faire du morphing sur des caractéristiques bien identifiées. La seule raison pour parler des AE simples était d’introduire la notion de variables latentes.
Les auto-encodeurs variationnels (VAE) rajoutent deux ingrédients supplémentaires par rapport aux AE simples qui leur permettent de réaliser la promesse de la figure 2.
- Le point de départ est l’idée intuitive qu’une image est toujours le résultat d’un processus aléatoire si bien que deux versions d’un même visage devraient être encodées par des points proches dans l’espace latent. Dit autrement, deux points dans l’espace latent dont la distance est inférieure à un certain seuil devaient être considérés comme indiscernables l’un de l’autre. Dès lors, plutôt que d’encoder chaque image de manière déterministe par un point λ dans l’espace latent, un VAE va choisir au hasard un point λ* proche de ce point λ. Plus précisément, l’encodeur d’un VAE calcule une distribution de probabilité centrée sur λ et d’écart-type σ, les deux étant appris par l’encodeur qui comporte en l’occurrence deux modules comme l’illustre la figure 4.
Figure 4 : Le générateur d’un VAE comporte deux parties dont l’une détermine la moyenne λ et l’autre la variance σ d’une distribution normale dont on échantillonne un point λ* au hasard dans l’espace latent.
En ce sens les VAE sont donc des modèles stochastiques, ils introduisent une part d’aléa dans le processus de génération. Ce processus de floutage délibéré incite le VAE à découvrir des encodages efficaces qui jouissent des propriétés de continuité souhaitées et remplace les conditions de parcimonie des AE simples.
- A chaque image en entrée correspond donc un point tiré au hasard selon le processus décrit précédemment. L’ensemble des points associés à toutes les images de l’ensemble d’entraînement forment donc un nuage de points dans l’espace latent. A priori, la forme de ce nuage est arbitraire. Si toutefois nous parvenions à faire en sorte que ce nuage ait une distribution simple et bien déterminée nous pourrions alors échantillonner des points selon cette même distribution pour créer, grâce au décodeur, des images aux propriétés statistiques identiques à celles de l’ensemble d’entraînement. Pour forcer le nuage de point à avoir une forme simple (une loi normale) les VAE introduise, en plus du coût de reconstruction, un terme supplémentaire dans la fonction de coût qui pénalise les nuages de points dont la distribution d’écarte trop d’une loi normale standard
[4].
L’expérience a démontré qu’en plus propriétés de continuités déjà évoquées les VAE avait par ailleurs des propriétés arithmétiques qui les rendent très utiles pour la retouche d’image avancée. Ainsi peut-on identifier une direction « sourire » ou une direction « lunettes » dans l’espace latent qui permettent de moduler l’expression d’une photo (figure 5). C’est propriétés sont similaires aux propriétés arithmétiques des Word Embeddings dans le domaine linguistique.
Figure 5 : Application du vecteur « sourire » et du vecteur « lunette » à plusieurs exemples.
Pour trouver ces directions dans l’espace latent, rien de plus simple : pour construire un vecteur « sourire » il suffit de soustraire le vecteur représentatif d’un visage triste à celui d’un visage souriant (ou de faire une moyenne de telles différences).
Les Generative Adversarial Networks (GAN)
L’état de l’art en matière de génération d’images réalistes ne repose plus aujourd’hui sur les VAE mais sur une nouvelle classe de modèles génératifs inventée en 2014 par Ian Goodfellow et appelés Generative Adversarial Networks [GAN]. Les GAN sont intéressants pour leurs performances mais, plus encore peut-être pour l’innovation conceptuelle qu’ils représentent dans le domaine du Deep Learning. Yann LeCun, directeur de recherche du labo Facebook AI Research dit à ce propos : « Les GAN sont l’idée la plus intéressante (en AI) que j’ai vue depuis 10 ans ! » [YLC].
On a coutume de les introduire au moyen d’une analogie avec l’activité de contrefaçon d’un faux monnayeur et, faute d’une meilleure idée, nous ne dérogerons pas ici à cette tradition. A bien y réfléchir un faux monnayeur et un modèle génératif ont effectivement des objectifs similaires : le premier cherche à duper l’autorité en charge d’émettre la monnaie officielle en confectionnant des faux billets réalistes alors que le second doit produire des images crédibles capables de leurrer des humains.
Un système GAN est constitué de deux réseaux de neurones en compétition comme l’illustre la figure 6.

https://weave.eu/app/uploads/2018/03/gan.png
Figure 6 : Un système GAN composé d’un générateur chargé de créer des images réalistes de digits manuscrits par transformation d’un bruit aléatoire et d’un discriminateur chargé de distinguer les vraies images des images fictives. Le discriminateur est basé sur un réseau de convolution (CNN). Le générateur utilise une forme de CNN inversé.
Le premier, appelé le générateur, a pour objectif de créer des images fictives crédibles qui ressemblent à celles d’un ensemble d’entraînement. Ce générateur fonctionne sur le même principe que le décodeur d’un AE ou d’un VAE représenté sur la figure 3 : il apprend à convertir du bruit (un point tiré au hasard dans l’espace latent) en une image. Mais, alors qu’un AE ou un VAE apprenait son « métier » en minimisant une fonction de coût statique, les GAN exploitent un mécanisme d’évaluation dynamique beaucoup plus puissant. Ils délèguent le contrôle qualité à un second réseau de neurones, appelé le discriminateur, qui va progressivement apprendre à distinguer les vraies images des fausses sur la base d’exemples connus. Ce discriminateur est entraîné sur un mode supervisé de la manière suivante :
- On échantillonne quelques dizaines d’images réelles de l’ensemble d’entraînement auxquelles on attribue l’étiquette « vraie ».
- On échantillonne ensuite quelques dizaines d’images fictives confectionnées par le générateur à partir de points tirés au hasard dans l’espace et auxquelles on attribue l’étiquette « fausse ».
- On fusionne les deux échantillons et l’on entraîne le discriminateur à prédire correctement les étiquettes, « vraie » ou « fausse » de chaque image de cet ensemble. Le discriminateur apprend en fait une probabilité pour une image d’être vraie.
On fige ensuite le discriminateur dans cet état puis on entraîne le générateur à tromper le discriminateur aussi souvent que possible de la manière suivante :
- On fabrique de nouvelles images fictives grâce au générateur.
- On soumet ces nouvelles images au discriminateur.
- On optimise le générateur pour que le discriminateur attribue (à tort) l’étiquette « vraie » aux images fictives aussi souvent que possible.
On itère ce processus. A chaque étape le générateur produira, si tout se passe bien, des images un peu plus réalistes, ce qui contribuera à renforcer le discernement du discriminateur, ce qui obligera le générateur à se surpasser à l’étape suivante et ainsi de suite. L’objectif de cette compétition, ou de ce jeu si l’on préfère, est de parvenir à un équilibre où le générateur parvient à reproduire des images indiscernables des originaux tandis que le discriminateur attribue des étiquettes correctes une fois sur deux. La figure 7 montre 20 chambres à coucher synthétisées par un GAN.
Figure 7 : Des chambres à coucher fictives “imaginées” par un GAN. A vous de juger !
La recherche d’un équilibre stable
[5], dans un jeu est un problème beaucoup plus délicat que l’optimisation d’une fonction de coût si bien que la description précédente n’est qu’une esquisse conceptuelle qui doit en réalité s’accompagner de nombreux trucs et astuces, d’expérimentations et de patience pour donner des résultats probants. Cette partie du Deep Learning reste à ce stade plus proche de la magie noire que de la science fondée sur des justifications robustes. Une partie de la difficulté de l’entraînement des GAN tient à l’inadaptation des outils existants du Deep Learning
[6] conçus dès l’origine pour rechercher des minimas et non pas des situations d’équilibre.
En examinant les images de la figure 7 on peut être pris de doute et penser que le GAN s’est simplement contenté de copier des images de chambre à coucher existantes. Il faut cependant garder à l’esprit que le générateur, voir la figure 6, ne « voit » jamais une image directement ! C’est indirectement, par le biais des retours que lui fournit le discriminateur, qu’il apprend à construire ces simulacres. En ce sens, l’entraînement d’un GAN s’apparente à une forme d’apprentissage par renforcement où le discriminant fournirait une récompense au générateur mais où cette récompense deviendrait de plus en plus difficile à obtenir.
Bien qu’ils produisent des images très nettes, pour des raisons d’ailleurs encore mal comprises, les GAN n’ont pas un espace latent aussi bien structuré et continu que les VAE.
Figure 8 : une esquisse et l’image photo-réaliste générée par Pix2Pix qui utilise un cGAN
Notons enfin qu’il existe d’innombrables variantes des GAN pour différents usages. Ainsi les cGAN, ou Conditional GAN, sont-ils capables de générer des images de manière conditionnée. Plutôt que des générer des images aux hasard comme le font les GAN, ils gérèrent des images différentes selon une information qu’on leur fournit en entrée. Le système Pix2Pix capable de traduire une esquisse en une image photo-réaliste utilise un tel modèle cGAN, voir la figure 8 et [PIX].
3. Pas encore de e-Picasso mais…
Nous voilà bien équipé pour répondre à la question initiale : qu’en est-il de la créativité de systèmes génératifs comme les VAE ou les GAN ? Bien qu’ils fonctionnent sur des mécanismes différents, ces systèmes ont en commun l’objectif de base qui consiste, dans un premier temps, à apprendre une distribution de probabilité sur des objets complexes, comme des images, puis, dans un second temps, à générer des objets similaires par échantillonnage de le distribution apprise. Voilà donc à quoi se résume toute leur « créativité ». Faut-il préciser dans ces conditions qu’un e-Picasso n’est pas pour demain ? [FPI].
Pour aller un peu plus loin dans l’analyse, dressons un parallèle entre les limitations des modèles d’apprentissage supervisé et celles des modèles génératifs. Les capacités prédictives des modèles actuels reposent, on le sait, sur la possibilité de faire des prédictions par interpolation de la variable cible à partir d’exemples connus à condition de postuler une régularité suffisante dans les données [MAL, LEM]. En ce sens, les prédictions de ces modèles ne sont donc que des généralisations locales à partir d’observations similaires à celle pour laquelle une prédiction est souhaitée. On conçoit bien dès lors que les modèles prédictifs actuels sont incapables d’abstraire un apprentissage dans un domaine pour en tirer parti dans un autre domaine éloigné ou encore de planifier une stratégie à long terme dans le cadre d’un apprentissage par renforcement. Ces aptitudes seraient des formes de généralisation à grande échelle [DLP] aujourd’hui inaccessibles à l’IA. La situation est analogue pour les modèles génératifs. Eux aussi, présupposent une forme de régularité dans la distribution des exemples dans le sens où un nombre limité d’entre eux doit permettre d’imaginer de nouveaux exemplaires similaires.
Les capacités d’ « imagination créative » des modèles génératifs actuels sont aussi limitées que le sont les capacités de généralisation ou d’abstraction des modèles prédictifs et ceci pour les mêmes raisons.
Figure 9 : Reproduction - Les « montres molles » de Salvador Dali.
Sans vouloir nous lancer dans d’aventureuses spéculations sur la nature profonde de la création artistique, essayons malgré tout de la comparer aux balbutiements des modèles génératifs décrits précédemment. Au moins deux caractéristiques distinguent ici l’homme de la machine. La première est que la créativité artistique prend ses racines dans une expérience multi-sensorielle qui s’échelonne sur la vie d’un artiste et va donc bien au-delà d’un simple échantillonnage d’une seule catégorie de données (images, textures, sons, textes etc…). Le seconde est qu’un artiste est habité d’une intention, celle de communiquer un monde intérieur ou d’enrichir celui des destinataires de son œuvre avec qui il partage une communauté d’expériences qui font une vie humaine. Lorsque Salvador Dali peint « La persistance de la mémoire » illustrée dans la figure 9, il crée une œuvre qui présuppose que l’observateur sait, non seulement ce qu’est une montre, mais ce qu’est la gravitation et que les montres réelles ne sont pas molles et que de cette incongruité naîtra une allégorie qui tourne en dérision notre obsession du contrôle du temps.
Les affirmations comme quoi le prochain Rembrandt pourrait être un robot ne sont donc que des fantasmes (pour rester modéré) de journalistes en quête de sensationnalisme.
Les machines apprennent des lois statistiques mais n’ont pas accès, pour l’instant, à la sémantique des objets qu’elles manipulent. Si elles savent produire des images réalistes de chambres à coucher elles n’ont en revanche pas la moindre idée des usages possibles d’un lit ou d’un miroir.
Si l’on veut examiner sérieusement l’apport de modèles génératifs dans un contexte artistique ou créatif il faut vraisemblablement abandonner le paradigme d’une IA conçue en tant qu’externalisation d’un processus cognitif et envisager plutôt celui d’une Intelligence Augmentée. Dans ce cadre, il s’agit souvent pour une « IA » de dispenser le créateur d’un ensemble de tâches considérés comme fastidieuses ou peu créatives justement : coloriser une image, générer des détails ou encore écrire un accompagnement pour une mélodie. Libéré de ces contingences subalternes, celui-ci pourrait alors donner la pleine mesure de son talent créateur ! Est-il bien réaliste toutefois de vouloir dispenser un artiste de toute forme de technicité, qu’elle soit laborieuse à acquérir ou fastidieuse à exécuter ? Rien n’est moins sûr.
Cette question ainsi que tout le thème de l’intelligence augmentée seront abordées en détail par notre expert UX dans le prochain article de cette série.
Découvrez la deuxième partie de cet article : “Le Machine Learning décrypté”, en cliquant ici
Notes
[1] En pratique le schéma d’interconnexion pour un AE d’image utilise les éléments d’un réseau de convolution (CNN), maie le principe reste le même.
[2] Comme la somme des carrées des différences (xi – x’i )2 par exemple.
[3] Il est possible d’exploiter d’autres contraintes que le goulet d’étranglement pour forcer un AE à découvrir un espace de variables latentes. L’ajout d’un signal de bruit aux données en entrée par exemple ou des contraintes de parcimonie qui limitent le nombre de neurones actifs dans la couche centrale sont deux possibilités [DLP].
[4] Pour les geeks : c’est la divergence de Kullback-Leibler entre la distribution empirique des points représentatifs dans l’espace latent et la loi normale standard en d dimension où d=dim(espace latent).
[5] Techniquement il s’agit d’un équilibre de Nash entre deux joueurs qui cherchent chacun à optimiser leur stratégie, ayant connaissance des règles du jeu qui s’appliquent aux deux.
[6] Comme la rétropropagation et descente de gradient stochastique.
Références
- [ROB] Les robots seront-ils les artistes de demain ? Bourcier, P. de Filippi, La Tribune – 2 mars 2018
www.latribune.fr/opinions/tribunes/les-robots-seront-ils-les-artistes-de-demain-770046.html - [FPI] Et si le futur Picasso était un robot ? Paquette, L’express – février 2018
lexpansion.lexpress.fr/high-tech/et-si-le-futur-picasso-etait-un-robot_1986771.html - [PIX] Image-to-Image Translation in Tensorflow, C. Hesse
affinelayer.com/pix2pix/ - [YLC] An introduction to Generative Adversarial Networks, Glover – août 2016
blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/ - [GAN] Generative Adversarial Networks, J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio arXiv:1406.2661v1[stat.ML] – juin 2014
- [MAL] Science des données – cours au Collège de France, Stéphane Mallat – janvier 2018.
college-de-france.fr/site/stephane-mallat/inaugural-lecture-2018-01-11-18h00.htm - [DMG] Dual Motion GAN for Future-Flow Embedded Video Prediction, Liang, L. Lee, W. Dai, E. P. Xing, arXiv:1708.00284v2[cs.CV] – août 2017
- [LEM] L’IA au-delà des clichés, section II.2, Lemberger, N. Parent, A. Régent – février 2018
ia2.weave.eu/ - [DLP] Deep Learning with Python, Chollet, Manning Publications – novembre 2017
- [TAE] Tutorial on Variational Autoencoders, Doersch, arXiv:1606.05908v2[stat.ML] – août 2016.
- [IGF] Generative Adversarial Networks, Goodfellow, vidéo NIPS 2016 – avril 2017
www.youtube.com/watch ?v=AJVyzd0rqdc
Mots clefs : machine learning Intélligence Artificielle créativité modèles génératifs
Et aussi > On en parle :
L’IA au service de la cybersécurité pour la détection d’anomaliesOthmane HAROURI Pirmin Lemberger 25 février 2019
De la Smart City à la Safe CityArthur Chedeville 18 juillet 2018
Nos offres sur le sujet ! Digital & Innovation
« L’Intelligence Artificielle, au-delà des clichés » - Livre blanc - Comprendre pour décider - Découvrez l’Intelligence Artificielle pour l’intégrer dès maintenant à vos enjeux stratégiques ! Téléchargez gratuitement
weave – Collectif en conseil augmenté -Le Mur L’expérience weave Nous rejoindre Une rencontre

Résultat de recherche d’images pour ’weave.eu’
Source : https://weave.eu/ia-creative/
20.
Quand l’intelligence artificielle affole le marché de l’art - Par Jean-Max Koskievic– Document ‘contrepoints.org’
Un collectif d’artistes français a réussi à vendre chez Christie’s une œuvre uniquement signée par un algorithme, à un prix jamais vu. L’intelligence artificielle à la conquête du marché de l’art ? Pas si vite…
Chez Christie’s en octobre 2018, dans une vente aux enchères lors de laquelle une œuvre d’Andy Warhol s’est vendue pour 75 000 dollars et une œuvre de Roy Lichtenstein pour 87 500 dollars, une œuvre d’art générée par une Intelligence Artificielle (IA) s’est envolée à 350 000 dollars (432 500 dollars prime acheteur incluse) pour une estimation entre 8 000 et 11 500 dollars. Le portrait intitulé Portrait d’Edmond de Belamy (2018) a été réalisé par OBVIOUS, un collectif parisien d’artistes grâce à un algorithme d’IA.
Le prix à six chiffres réalisé par cette œuvre paraît disproportionné au regard des prix atteints lors de cette vente par les œuvres de deux des artistes (humains) les plus chers du marché de l’art et est évidemment le résultat d’un battage médiatique hors du commun durant les deux mois précédant la vente, battage qui a débuté par un article accrocheur dans le magazine en ligne de Christie’s et qui a ensuite fait tache d’huile auprès des médias spécialisés puis traditionnels.
Mais cette « recette de cuisine » bien connue sur le marché des ventes aux enchères d’œuvres d’art d’exception n’est pas une explication suffisante, c’est plutôt la cristallisation de tous les mythes autour de l’IA, de ses possibilités actuelles et de son potentiel, qui se sont catalysés dans la vente de cette œuvre d’art, mythes évidemment entretenus par son lot d’affirmations infondées voir même de contre-vérités comme nous allons le voir.
Ainsi, comment une œuvre d’art d’un collectif d’artistes français inconnus, signée uniquement de la formule servant de nom à l’algorithme qui l’a créé, peut-elle contourner le marché primaire de l’art, se trouver directement en vente aux enchères chez Christie’s et ensuite obtenir un prix aussi élevé ?
Qu’est-ce que l’art créé par IA ?
Lors de l’annonce de la vente aux enchères de cette œuvre, il était courant de lire que cette œuvre était « le premier portrait réalisé par une Intelligence Artificielle ». Pur mythe, la réalité est toute autre. Les artistes utilisent l’IA pour créer de l’art depuis plus de 50 ans.
L’exemple le plus marquant est le travail d’Harold Cohen et son programme de création artistique, AARON. L’artiste américaine Lillian Schwartz, pionnière dans l’utilisation de l’infographie dans l’art, a également expérimenté l’IA. Traditionnellement, ces artistes utilisant l’ordinateur pour générer de l’art devaient écrire un code détaillé qui spécifiait à l’ordinateur les règles de l’esthétique qu’ils souhaitaient.
En revanche, l’œuvre vendue chez Christie’s fait partie d’une nouvelle tendance d’œuvres d’art créées par IA apparue au cours des deux dernières années. Ce qui caractérise cette nouvelle vague, c’est que l’algorithme utilisé par les artistes apprend tout seul l’esthétique en regardant de nombreuses images à l’aide d’une technologie d’apprentissage automatique (Machine Learning).
L’algorithme génère alors de nouvelles images qui suivent l’esthétique qu’il a appris. L’outil le plus largement utilisé par de nombreux concepteurs d’art par IA est les réseaux adverses génératifs (en anglais Generative Adversarial Networks ou GANs), une technologie qui permet à un ordinateur d’étudier une bibliothèque d’images (ou de sons), de créer son propre échantillon en fonction de ce qu’il a appris, de tester cet échantillon par rapport au support original, d’essayer par lui-même de créer une œuvre originale et de l’améliorer progressivement par un processus d’essais et erreurs assez simple (qui cherche grossièrement à minimiser la distance entre l’échantillon généré et le vrai échantillon, jusqu’à la convergence des deux).
Plus techniquement, le GAN met en compétition deux intelligences artificielles (ou réseaux de neurones) reposant sur des algorithmes d’apprentissage non-supervisés, initialement introduits en 2014 par Ian Goodfellow (bel ami en français d’où le nom du portrait vendu par Christie’s).
La première (le Générateur) va créer des images à partir d’une base de données d’images qui lui sont fournies. La seconde (le Discriminateur) a pour rôle de détecter si les images sont réelles (proviennent de la base de données initiale d’images) ou bien si elles sont le résultat du Générateur.
La tension entre ces deux IA pousse chacune d’elle à apprendre et à s’améliorer. En d’autres termes, il s’agit d’une sorte de test de Turing pour Intelligences Artificielles. Cet apprentissage peut être modélisé comme un jeu à somme nulle (lorsqu’une IA gagne en discriminant bien, c’est que l’autre IA a échoué à la berner). Lorsque ce processus s’applique à la création d’œuvre d’art, on parle de CAN (Creative Adversarial Networks). Le CAN produit ainsi de nombreuses images et les œuvres d’art résultant de ce va-et-vient entre ces deux réseaux de neurones artificiels — comprenant des estampes, des vidéos ou encore des installations multimédias — sont souvent d’un inquiétant réalisme.
L’art créé par IA sonne-t-il la fin des artistes ?
Là aussi le battage médiatique orchestré par Christie’s autour de cette œuvre a laissé entendre (et écrire) qu’il s’agissait d’une « œuvre d’art réalisée par un ordinateur sans intervention humaine ». Faux et archifaux ! Le processus créatif en question ici implique fortement l’artiste.
L’artiste choisit tout d’abord une collection d’images pour alimenter la base de données servant à entraîner l’algorithme initial (c’est le travail de pré-curation de l’artiste). Dans le cas du Portrait d’Edmond de Belamy (2018), OBVIOUS a sélectionné d’un ensemble de 15 000 portraits réalisés par des artistes célèbres des six derniers siècles. Ces images sont transmises à un algorithme génératif d’apprentissage qui tente d’imiter ces entrées.
Enfin, l’artiste passe au crible de nombreuses images de sortie pour constituer un choix final et choisir les images qui lui paraissent les plus intéressantes (c’est le travail de curation de l’artiste). Heureusement, l’algorithme ne parvient pas à faire des imitations parfaites des images initialement entrées, et génère plutôt des images déformées généralement assez surprenantes.
En effet, s’il réussissait à imiter parfaitement les données, les œuvres générées n’auraient aucun intérêt artistique, ce ne serait que de pures copies ! Comprendre cela est crucial pour caractériser ce qu’est réellement l’art créé par IA, c’est-à-dire pas uniquement des images qui en résultent d’un algorithme mais un processus créatif dans son ensemble comprenant l’ensemble des données choisies et conservées, l’algorithme sélectionné et ses paramètres, et évidemment le choix final de l’artiste.
Vendre aux enchères de l’art créé par IA : une première ?
Là encore le mythe orchestré par Christie’s a bien fonctionné, laissant écrire que ce sera « la première œuvre d’art réalisée par IA jamais vendue aux enchères ». La réalité là aussi est toute autre. Lors d’une vente aux enchères caritative organisée par Google à San Francisco en 2016, 29 œuvres réalisées par IA ont été vendues pour un total de 98 000 dollars, l’œuvre GCHQ de l’artiste londonien d’origine turque Memo Akten ayant obtenu 8 000 dollars, le prix le plus élevé de la vente.
En 2017, une œuvre d’art crée par AICAN (Artificial Intelligence Creative Adversarial Network), une IA crée par le Art & AI Lab de la Rutgers University, a été vendue pour 16 000 dollars lors d’une vente aux enchères de caritative à New York.
Pour conclure, il est aujourd’hui imprévisible de savoir comment le prix élevé réalisé chez Christie’s finira par faire basculer le marché de l’art créé par IA. L’histoire du marché de l’art contemporain a montré qu’il était toujours dangereux pour un artiste d’avoir une telle flambée des prix sur le marché secondaire (les ventes aux enchères) avant même de passer par le marché primaire. Ceci dit, comme l’a écrit Anatole France « l’avenir est un lieu commode pour y mettre des songes ». À méditer…
Nos dossiers spéciaux : Art contemporain Christie’s Intelligence artificielle Vente aux enchères
Auteur : Jean-Max Koskievic est Professeur Associé à Paris School of Business (ex ESG Management School). Ses thèmes de recherches portent sur la participation financière et les négociations en environnement incertain, ainsi que sur le marché de l’art.
Référence indiquée : Artificial Intelligence & AI & Machine Learning By : Mike MacKenzie - CC BY 2.0 – Photo
ContrepointsBas du formulaire
qui couvre l’actualité sous l’angle libéral. Contrepoints ne peut exister sans vos dons - FAIRE UN DON - Sciences et technologies 23 janvier 2019
© Contrepoints.org | Mentions légales - Source : https://www.contrepoints.org/2019/01/23/335364-quand-lintelligence-artificielle-affole-le-marche-de-lart
21.
L’Intelligence Artificielle aidera-t-elle l’homme à devenir plus humain ? par Alexandre | Déc 8, 2018 | Prospective | Document ‘inprincipio.xyz’
Illustration - L’intelligence est une notion conceptuelle et très relative. Nous pourrions tous tenter d’en donner une définition, ne nous prouvant à nous-mêmes que finalement, nous qui nous pensions suffisamment intelligent pour tenter de la décrire, sommes sans doute surtout artificiellement intelligents.
Wikipedia nous en dit simplement ceci : « l’intelligence se définit comme l’ensemble des processus de pensée d’un être vivant qui lui permettent de s’adapter à des situations nouvelles, d’apprendre, ou de comprendre ». La belle affaire.
Un animal est un être vivant que certains mécanismes neuronaux autorisent à s’adapter voire à apprendre.
Le Larousse, lui, nous indique que c’est « l’ensemble des fonctions mentales ayant pour objet la connaissance conceptuelle et rationnelle ». Ou comment définir un concept brumeux, évasif, insaisissable à l’aide d’autres concepts qui ne le sont pas moins : connaissance, rationalité, fonctions mentales… Nous voilà bien avancés.
Certains avancent qu’il est tout aussi impossible à l’intelligence de se définir elle-même qu’un œil ne peut se regarder lui-même et que ceci expliquerait les difficultés que nous rencontrons à définir avec simplicité et précision ce qu’est l’intelligence (sous-entendu, se regardant elle-même pour tenter de s’appréhender).
Intelligence artificielle et état de l’art
Parmi les nombreuses tentatives de définition de ce qu’est l’intelligence, j’ai entendu un jour un homme décrire l’intelligence comme « la faculté pour le cerveau de faire des liens entre des choses qui n’en avaient apparemment pas ».
Cette phrase a le mérite de décrire ce dont est déjà capable la machine aujourd’hui et ce, en quelques mots. Vu sous cet angle, et sans vouloir vous faire peur, la machine est déjà capable de surpasser les capacités du cerveau humain.
L’IA moderne est en effet bâtie sur 2 fondamentaux principaux :
- Les mathématiques
- Des volumes de données colossaux
Et sur ces bases, des algorithmes mathématiques ont été créés permettant à la machine d’établir des corrélations. J’insiste ici, pas des « causalités » mais des « corrélations ».
Ainsi, en brassant par exemple des millions d’exemples de comportement de consommateurs, l’on est aujourd’hui capable de savoir que, si vous avez acheté un disque de Johnny lundi et que vous avez mangé des choux de Bruxelles mardi, alors il y a 77.6% de chance que vous achetiez une Seat mercredi.
Les capacités de mémoire et surtout de traitement de l’information du cerveau humain n’aurait jamais pu parvenir à tirer de telles conclusions probabilistes. Et qui fonctionnent statistiquement.
Sous cet angle, la machine serait donc déjà beaucoup plus intelligente que l’être humain. Elle a « la faculté de faire des liens entre des choses qui n’en avaient apparemment pas »
Mais est-ce pour autant de l’intelligence ? D’autant que les techniciens ayant développé ces algorithmes laissant la machine trouver des corrélations par l’exemple (algorithmes dits de Deep Learning ou de réseau de neurones convolutifs) sont eux-mêmes dans l’incapacité la plus totale d’interpréter les conclusions et l’autoréglage de leur machine permettant d’y parvenir !
Pourtant, la technologie fait à cet égard des prouesses : un véhicule autonome se déplace par exemple en analysant de façon dynamique des images, ou plutôt des pixels dans les images. C’est à force de millions d’exemples qui ont été donnés à la machine de façon supervisée par l’humain qu’elle fut en mesure de reconnaître seule lescaractéristiques clefs des obstacles (automobiles, panneaux, piétons, etc…) afin de pouvoir les éviter à l’avenir.
C’est aussi avec une approche très vectorielle (on parle ici d’IA connexionniste) quela reconnaissance vocale fait des prouesses : la longueur d’une onde sonore, sa fréquence, le tout passé à la moulinette de millions d’exemples de mots prononcés permettent à la machine d’entendre ce qui est dit. On parle de Speech-to-text.
Mais en définitive, les grandes merveilles que touchent du doigt l’IA aujourd’hui sont seulement de 2 ordres :
- Le domaine de la perception (visuelle, par la reconnaissance d’images ou vocale)
- Le domaine de l’analyse prédictive (l’exemple du CD de Johnny, des choux de Bruxelles et de la future Seat).
L’intelligence artificielle intelligente
L’objet n’est pas ici d’approfondir les techniques mais, par ces exemples, vous devez toucher du doigt que l’IA telle que nous la connaissons aujourd’hui est … « con comme un balai ». Tout au plus sait-elle dire « chaise » en voyant une chaise.
Elle ignore ce qu’est conceptuellement une chaise, à quoi sert une chaise, voire mieux, à quoi pourrait servir une chaise en en détournant l’usage premier, par exemple de monter dessus pour changer une ampoule ou de la mettre au feu pour se chauffer.
Le terme d’Intelligence est donc très largement usurpé lorsqu’on parle de l’état de l’art de l’IA à ce jour.
Toutefois, des laboratoires de recherche, comme In Principio, travaillent à lever ce verrou technologique. Et l’on parle ici d’IA tant connexionniste que symbolique. C’est-à-dire à même de traiter le champ de représentation des connaissances comme le décrivent les sciences cognitives, de façon conceptuelle.
Prenons un exemple : lorsque vous et moi sommes au restaurant et que nous parlons d’une bouteille : en toile de fond, sans que vous le conscientisiez, se présente à vous le concept même de bouteille : un contenant (qui est un concept primitif) rigide, avec un contenu, de type liquide, ayant pour usage d’être bu. Mais si nous nous retrouvions tous sur une plage devant un club de plongée, et que je vous disais « avez-vous pris vos bouteilles » ? Il se passerait autre chose en toile de fond dans votre cerveau. Le concept appelé serait toujours un contenant rigide, avec un contenu, cette fois gazeux et ayant pour usage de respirer sous l’eau. Et votre cerveau aurait alors, seul, désambiguisé le mot « bouteille ».
Le mot est toujours l’émanation, parfois très approximative d’ailleurs, de la pensée. Il est toujours précédé de la pensée, de ses concepts et de ses patterns syntaxico-sémantiques.
Si nous parvenions donc à recréer ces patterns syntaxico-sémantiques, ces concepts, cette représentation des connaissances du cerveau humain dans une base de données parcouru par un algorithme programmé dans le cadre d’un autre domaine de l’IA qu’on appelle « la résolution de problèmes », alors la machine serait capable de penser, de raisonner.
Mieux, et c’est aussi un sujet sur lequel nous travaillons chezIn Principio : puisqu’il n’y a d’intelligence que par la faculté d’apprendre, l’on pourrait imaginer dessiner un algorithme capable de créer lui-même ses propres concepts sans qu’ils ne lui aient été enseignés par l’humain au préalable.
Prenons un exemple : vous avez injecté à la main, dans la machine, les concepts, leurs attributs et leurs dérivés de « boire », « lever », « bouteille », « bouche » (un des attributs de « bouche » pouvant être par exemple de « goûter », c’est-à-dire un autre concept, etc…) rendant ainsi la machine capable de comprendre une situation appelant ces concepts en toile de fond. Puis vous présentez un texte inédit à la machine disant à peu près ceci : « il prit la bouteille, en versa le contenu dans un VERRE qu’il porta à ses lèvres pour se sustenter » => eh bien la machine, sans jamais l’avoir rencontré auparavant deviendrait capable de commencer à s’autoforger le concept de VERRE en raccrochant ce concept au contexte présenté, comme nous le ferions nous-mêmes. Ici, elle serait à même de comprendre que le verre est aussi un contenant, à même de réceptionner le contenu d’une bouteille, objet intermédiaire semble-t-il entre le contenant bouteille et la bouche.
Saisissez bien la portée de l’exemple : rencontrant pour la 1ère fois un nouveau concept (celui de verre), elle devient capable de le modéliser dans son cerveau artificiel. Elle deviendrait alors capable d’apprendre, d’abord de façon supervisée (on la guiderait pour qu’elle ne tire pas de conclusions erronées sur le concept de verre), puis seule. Elle apprendrait seul, par contextualisation, par analogie, ou par généralisation à partir de cas spécifiques. Comme nous le ferions nous-mêmes !
Quoi que l’état de l’art technologique, déjà capable de prouesses nous l’avons dit, puisse être associé à un niveau d’intelligence proche de zéro, vous comprenez que le monde tend vers ce que l’on nomme dans la profession « l’intelligence artificielle générale ». Et le monde entier y travaille, avec en première ligne les géants du numérique américains et chinois GAFAMI et autres BATX.
Tout ceci induit de grands débats contemporains (et ils sont fondés) autour de l’éthique, de la morale, de la disparition des emplois, etc…
Jusqu’où l’IA peut-elle aller trop loin ?
Pour autant, nous n’avons parlé jusqu’ici que de rationnalité. De capacité pour la machine de « réfléchir » ou sens raisonner. Demain de pouvoir par exemple discuter, échanger, expliquer, conseiller, argumenter, contre objecter, négocier, faire des hypothèses, etc…
Bref, des merveilles mais qui n’ont rien à voir avec les mythes lus ça et là dans la presse d’une IA capable d’avoir une conscience d’elle-même, d’empathie, de ressentir des émotions, voire d’être capable de spiritualité. Simuler des sentiments, pourquoi pas. En ressentir, ce n’est pas demain l’avant-veille.
Ce qui crée souvent la confusion aujourd’hui a trait à la capacité de créer. Alors qu’on pensait cela être chasse gardée de l’humain, l’on s’aperçoit, et déjà en l’état actuel de l’art, que la machine est capable de créer. C’est ce que l’on nomme dans le jargon scientifique « le modèle génératif ».
Reprenons l’exemple de la reconnaissance d’image qui permettra demain au véhicule autonome d’évoluer sur les mêmes routes que nous. Comment cela fonctionne-t-il ?
Prenons l’exemple de la faculté pour la machine de reconnaître un visage. La machine décompose l’image basse définition en dizaine de milliers de pixels. Elle effectue ensuite des regroupements : un groupe de pixels est formé puis analysé. Pour une interprétation humaine de la chose on dirait que la machine crée des formes (par exemple des ombres). En groupant à nouveau ces 1ers groupes, vont commencer à se dessiner des formes : une narine, l’arête d’un nez, etc… Ces nouveaux groupes vont être à nouveau regroupés : la machine forme ici un nez, là une oreille, là des yeux, etc… Et en regroupant ces éléments elle forme un visage et est en sortie capable de dire « OK, c’est un visage que vous m’avez présenté » (voire de qui est-ce le visage, mais ce n’est pas le propos).
Autrement dit, à coup de millions d’exemples de visages et d’essais/erreurs supervisés par l’homme, la machine a été capable d’apprendre à se régler automatiquement pour extraire les caractéristiques clefs de ce qu’elle perçoit comme étant un visage (2 yeux, un nez, une bouche, etc…).
Ce qu’on appelle le modèle génératif, c’est le fait de prendre l’algorithme à l’envers : c’est-à-dire que la machine n’extrait pas des caractéristiques d’une photo mais extrait une photo à partir de caractéristiques. Et c’est ainsi qu’elle « crée » des visages sortis de nulle part, des voitures entièrement inventées, des oiseaux inconnus sur la planète, etc…
Je vous invite à aller écouter la chanson Daddy’s Car, pour ceux qui sont fans des Beatles, où la machine, ayant bouffé des millions de musiques et en particuliers l’œuvre complète des Beatles a pu en tirer les caractéristiques musicales clef : harmonies, accords, rythmiques, mélodie, enchaînements mélodiques, etc..jusqu’à recréer ce qui ressemble au dernier tubes des 4 garçons dans le vent.
Bref, la machine stricto sensu « crée ».
Deux écoles peuvent s’opposer à cet égard. « Non, elle ne crée pas, elle a bouffé des millions d’exemples, et elle recrache un truc soi-disant nouveau à partir des datas qu’elle a digéré ; ça n’a rien à voir avec la créativité humaine ».
Laissez-moi vous donner un autre point de vue : un auteur écrivant un roman ne sera-t-il pas aussi inspiré de sa vie sociale, de ses parents, de ses lectures, des films qu’il aura vus par le passé…avant d’écrire son œuvre ?
La créativité, l’inventivité, que nous pensions être le propre de l’homme est en train d’être conquise par la machine… La question interroge, n’est-ce pas ?
Vers où et quoi l’IA va-t-elle acculer l’homme
Nous l’avons esquissé en parlant de créativité, ce qui est en train de se passer et ce qui va se passer dans les 40 prochaines années est tout bonnement un rattrapage et un dépassement de l’homme par la machine du point de vue du Logos.
Elle sera donc demain capable – et plus rapidement que nous – de raisonner, à partir d’un champ de connaissances aussi vaste que le champ des connaissances disponibles numériquement sur internet. Pensez-y : l’ensemble des œuvres littéraires numérisés, les milliards d’heures de vidéos postées, de blogs, de parutions scientifiques, etc… Toutes les connaissances de l’humanité depuis la nuit des temps réunies sur la toile lui seront accessibles. Elle sera capable, dis-je, de raisonner plus vite et mieux que nous, et de forger ses propres nouveaux concepts, en ayant une faculté inégalée d’induction de liens de corrélation – et de causalité cette fois – qui resteront à jamais inaccessibles à la limitation du cerveau humain.
Deux possibilités s’offrent alors à nous : fuir en se disant « on va tous mourir, bordel » ou bien commencer à réfléchir sur le devenir de l’homme.
Et je pense que c’est par le travail que se trouve la clef d’entrée. En effet, une machine capable des prouesses évoquées ci-dessus remplacerait nécessairement le travail. J’ai coutume de dire que la machine a remplacé le muscle dès les années 1970-1980. Nous vivons actuellement le remplacement du muscle-cerveau par la machine c’est-à-dire la disparition des jobs de ceux qui se servaient relativement peu de leurs cerveaux à titre professionnel : chauffeurs de taxi, opérateurs de saisie, etc..
Demain – disons après-demain – c’est l’ensemble de ceux qui se servent de leur raison (et même de leur créativité nous l’avons vu) qui verront leur emploi disparaître.
Le travail, étymologiquement encore, vient du latin Tripalium qui était un instrument de torture à 3 pieux. Le verbe travailler vient du latin populaire Tripaliare qui signifie torturer avec le Tripalium. Au XIIe siècle, le sens de travailleur devient « celui qui tourmente ».
On voit ici se dessiner ce qui pourrait faire largement débat : si le travail est une tourmente, une torture, au fond, qui ne nous sert finalement qu’à générer des revenus comblant nos besoins basiques primaires (manger, se loger, éventuellement se divertir), le sens du monde n’est-il pas naturellement d’aller vers la disparition du travail que l’on confierait pleinement à la machine ?
Les agriculteurs n’ont-ils pas vécu la disparition des heures de labeur (tiens, un autre terme bien négatif qui vient du latin Labor, la peine, l’effort), les agriculteurs n’ont-ils pas vécu la disparition des heures de labeur, dis-je, passée à retourner la terre en se brisant le dos comme une libération née de l’avènement des tracteurs ?
Finalement, la seule question qui subsisterait serait sociétale : si le travail disparait, comment payer les factures ? Mais, au fond, qui se soucie avec un tel questionnement du travail en lui-même ?
L’intelligence artificielle pourrait, nous l’avons compris, nous « libérer » du travail. Cela pose de nombreux problèmes philosophiques, pour ne pas dire religieux. N’est-il pas souvent dit que le travail est le propre de l’homme ?
Libéré de ce que l’on croyait être son propre, l’homme serait nécessairement conduit à se poser la question de sa raison d’être ici-bas. Si ce n’est pas le travail, celui qui fait se lever tôt pour gagner la croûte, quel peut donc bien être le propre de l’homme ?
Son élévation spirituelle semble jaillir à l’esprit comme une évidence. Qu’est ce qui semble bien être totalement inaccessible à la machine ? nous l’avons dit : émotion, conscience de soi, spiritualité, …
Le travail est un projet conscient auquel l’homme choisit (notion de libre-arbitre que n’a pas la machine) de donner ou non une forme aboutie. Ce n’est pas un travail aliéné, ni un travail aliénant.
Débarrassé de l’intellect et du mental, injectés dans la machine, l’homme en resterait doté mais pourrait alors exploiter pleinement ses autres facultés, spirituelles, se connecter au monde et aux autres, apprendre à exploiter l’énergie, au sens quantique du terme, celle qu’on ne voit pas mais qui ne connaît ni de limite de temps, ni d’espace.
Il pourrait enfin passer son temps à explorer le monde de l’ondulatoire, du vibratoire, développer ses 6e, 7e ou 8e sens puisque les 5 premiers pourraient tout aussi bien être théoriquement injectés dans la machine. Il pourrait enfin Être au monde, ayant mis en perspective le corpusculaire, devenu capable de l’observer du dehors, mettant ainsi beaucoup mieux en exergue la finitude du matériel, se rendant compte que le corps est lui-même une formidable machine créé par le grand programmateur mais qui n’est au fond aussi qu’une machine. Le génie du grand programmateur va bien au-delà de l’approche anthropomorphique. L’homme a été créé à son image, mais son image n’est pas que physique (ça c’est reproductible), elle est aussi métaphysique : elle dépasse la physique. L’IA marquera l’avènement ultime de la physique. Nous garderons la méta.
Vous pourriez aussi être intéressé par cet article : les9 choses que nous ne pouvez pas ignorer à propos de l’IA
Catégories : Prospective et IA Technique et technologie Usages et applications - Pour plus d’information >>> Nous contacter
Copyright © 2018 - InPrincipio.xyz | Suivez-nous sur Twitter |Mentions légales - Source : https://www.inprincipio.xyz/intelligence-artificielle-homme-plus-humain/
Autres travaux d’Alexandre qui sont accessibles :
Intelligence Artificielle : son réel impact sur notre quotidien par Alexandre | Oct 21, 2018 | Usages – « A en croire la presse, un mouvement colossal et comparable à une sorte de gigantesque tectonique des plaques socio-économiques seraient en train de se produire sous nos yeux. La Blockchain, pour ne citer qu’une des technos faisant trembler la planète... »
Intelligence Artificielle vocale et SEO par Alexandre | Juin 17, 2018 | Business – « Cette étude de Cap Gemini de fin d’année 2017 résonne comme un coup de tonnerre dans le Landerneau du commerce. Et, fait marquant, c’est autant le retail de type « brick-and-mortar » qui en sera impacté que l’intouchable digital retail, plus habitué, lui, à asséner... »
Comment conduire un projet d’IA dans son entreprise par Alexandre | Avr 15, 2018 | Business – « Nous sommes parfois interrogés sur la meilleure façon de conduire un projet d’intelligence artificielle au sein de son entreprise. Il est vrai que l’IA semble souvent laisser les spectateurs de son déploiement sur le bord de la route, médusés … »
Education : quand l’IA contraint l’Homme à tout revoir par Alexandre | Mar 25, 2018 | Prospective – « Aussi paradoxal que cela puisse paraître, à l’aube de l’avènement de l’intelligence artificielle, jamais l’intelligence humaine n’aura été plus capitale car, ramenée – de force – à ses propres fonts baptismaux… »
Publications antérieures sur l’IA postées sur ISIAS
’Faire connaissance avec l’Intelligence Artificielle (IA)’ par Jacques Hallard , vendredi 30 novembre 2018
’La nébuleuse des opérateurs économiques du numérique de l’électronique et des télécommunications’ par Jacques Hallard , dimanche 30 décembre 2018
’Offres et perspectives du numérique et de l’IA, usages et acceptabilité des utilisateurs, clients et consommateurs ; actions politiques et administratives en cours’ par Jacques Hallard , mardi 16 avril 2019 par Hallard
Conférence de Jacques Hallard, Ingénieur CNAM, sur l’Intelligence artificielle : miracle ou mirage, promesse ou périls ? Le vendredi 26 Avril 2019 à 18h30 à la Salle des Fêtes d’Eygalières 13 , lundi 22 avril 2019
Retour aux informations préliminaires
Remerciements à Alexandre et à tous/toutes les auteur-e-s des autres contributions qui ont été relayées dans ce dossier à usage strictement didactique et non commercial !
Auteurs : Jacques HALLARD, Ingénieur CNAM, consultant indépendant et Bastien Maleplate – 03/08/2019
Site ISIAS = Introduire les Sciences et les Intégrer dans des Alternatives Sociétales
Adresse : 585 Chemin du Malpas 13940 Mollégès France
Courriel : jacques.hallard921@orange.fr
Fichier : ISIAS IA et Arts L’intelligence artificielle dans les domaines artistiques en France et au Québec Canada.4
Mis en ligne par Pascal Paquin de Yonne Lautre, un site d’information, associatif et solidaire(Vie du site & Liens), un site inter-associatif, coopératif, gratuit, sans publicité, indépendant de tout parti.

http://yonnelautre.fr/local/cache-vignettes/L160xH109/arton1769-a3646.jpg?1510324931
— -

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
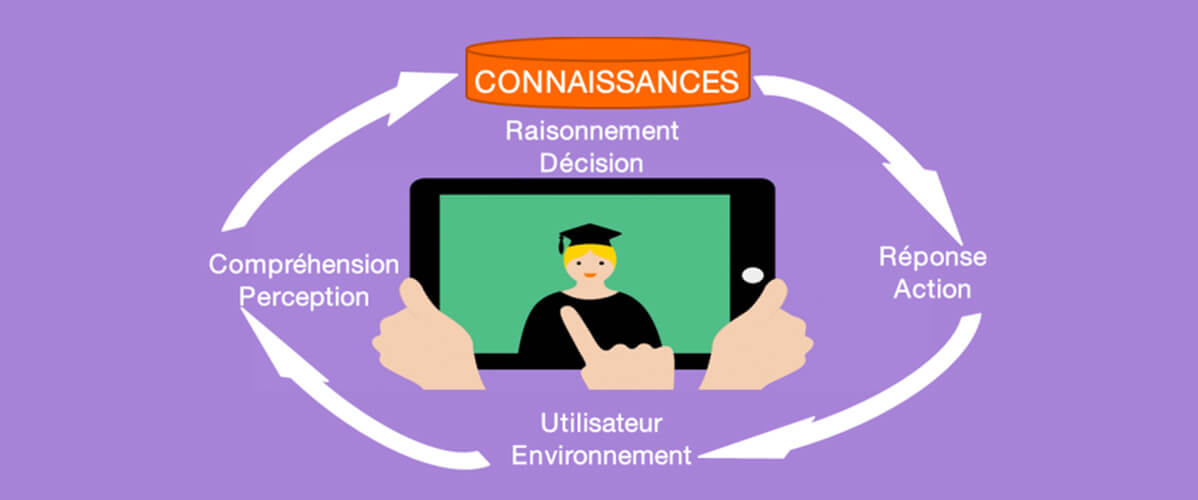{kind=link}
{kind=link}
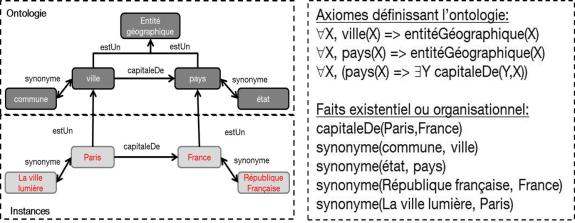{kind=link}
{kind=link}
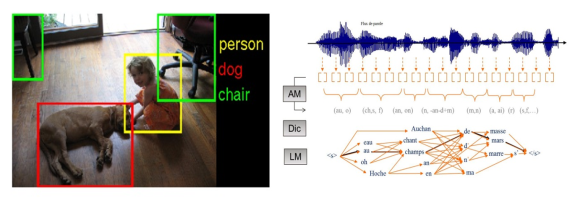{kind=link}
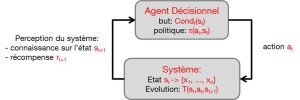{kind=link}
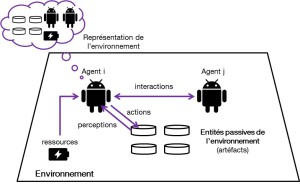{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
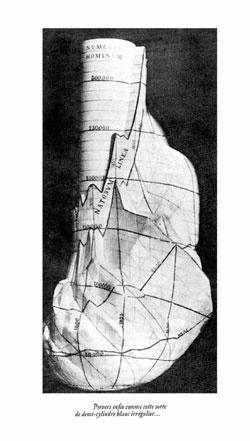{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}